
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 핀토스 프로젝트 2
- 아직도 실험 중
- 가테
- 핀토스 프로젝트
- 일지 시작한 지 얼마나 됐다고
- 글루민
- 노가다
- Project 1
- 글리치
- 바빠지나?
- 황금 장미
- 핀토스 프로젝트 3
- botw
- 핀토스 프로젝트 1
- multi-oom
- 마일섬
- 셋업
- 파란 장미
- 핀토스 프로젝트 4
- 제발흰박
- PINTOS
- 끝
- 자 이제 시작이야
- alarm clock
- 내일부터
- Today
- Total
거북이의 쉼터
(2022.04.10) Scheduling 본문
오늘은 드디어 스케줄링에 대해 정리하도록 한다.
0. mechanism과 policy
우선 스케줄러를 살펴보기 전에 mechanism과 policy에 관한 내용부터 살펴보자. mechanism은 작업을 "어떻게" 하는가에 관한 것이며, policy는 "무슨" 작업들이 일어나야 하는가에 관한 사항이다. 예를 들어 자동차를 목적지까지 운전한다고 하자. 자동차가 엑셀을 밟으면 움직이고, 브레이크를 밟으면 멈추도록 만드는 것은 mechanism의 영역이다. 그러나 차선을 맞춰서 어느 시점에 엑셀 또는 브레이크를 밟아서 어느 방향으로 자동차를 몰지는 policy의 영역이다. mechanism과 policy는 서로 구분하여 구현하는 것이 좋으며, 서로에게 영향을 주어서는 안 된다. 앞서서 든 예시로 설명하면, 자동차를 운전하는 사람이 바뀔 때 자동차 엑셀과 브레이크를 바꿔낄 필요가 없는 것과 같다. 이러한 개념을 Separation of mechanism and policy라고 부른다.
마지막으로 이러한 개념을 스케줄러에 적용해보자. 스케줄러는 작업(쓰레드)을 어떤 순서대로 실행할지를 결정한다. 스케줄러를 디자인할 때, 앞으로 실행되어야 할 작업을 ready list에 채워넣는 방법, 실행되고 있는 작업을 빼고 새로운 작업을 실행하는 방법 (context switching)을 구현하는 것은 mechanism의 영역이다. 이와 대비되어 준비된 작업 중 어떤 것을 선택해 실행할지를 결정하는 것은 policy의 영역이다. 즉 scheduling policy를 다루면서 우리는 전체 작업 중 어떤 작업을 선택해 실행할지를 결정하는 기준을 공부할 것이다.
1. 스케줄링 문제란?
그럼 지금까지 미뤄놨던 문제 설명을 하자. 대체 스케줄링은 왜 필요한가? 한정된 자원에 대해 더 많은 요청이 들어올 때, 해당 자원을 어떻게 분배할지는 중요한 문제이다. 게임 서버에 사람이 몰릴 때, 어떤 사람을 매칭 시켜줄 것인가, ML task들에 대해 GPU cluser는 어떻게 할당할 것인가 등 비슷한 문제는 많다. 이러한 경우, 어떤 작업에 자원을 우선적으로 배정할지를 답하는 것이 스케줄링이다. 스케줄링 알고리즘은 workload를 입력으로 받아 어떤 작업을 우선 실행할지 결정한다.
스케줄링을 살펴보기 위해 알고 가야 할 용어에는 다음이 있다.
- task/job : 지금까지는 "작업"이라고 번역했다. 정확히는 유저의 요청으로 들어오는 모든 것
(마우스 클릭, 웹 페이지 요청, 쉘 명령어 등등) 을 의미한다. - workload : 시스템이 수행해야 하는 작업의 집합
- overhead : 스케줄러 자체로 인해 파생되는 추가적으로 해야 하는 일의 양
- fairness : 다른 유저들이 제공받는 퍼포먼스의 양은 얼마나 공평한가?
- predictability : 시간에 걸쳐 퍼포먼스가 일정하게 유지되는가?
앞의 세 개는 비교적 자명한데, 아래 두 개는 좀 애매할 수 있다.
fairness의 경우, 다음과 같이 작업들이 주어진다고 하자.
| task # | time need to finish |
| 1 | 6 |
| 2 | 5 |
| 3 | 2 |
| 4 | 1 |
만약 정말 단순하게 모든 작업에 6의 시간을 암배한다면 이를 "공평"하다고 할 수 있을까? 4번 작업의 경우 필요하지도 않은 5 만큼의 시간이 더 주어지는 셈이다. 그래서 이를 구체적으로 정의하기 위해 나중에 Max-Min Fairness라는 개념을 배울 것이다.
predictability의 경우 작업을 실행할 때, 얼마나 일정하게 실행되는지를 나타내는 것이다. predictability는 애초에 왜 중요한 것일까? 첫 번째는 스케줄러에서는 어느 정도 미래를 예측할 필요가 있기 때문이다. 스케줄링에 있어서, 퍼포먼스를 예측하는 것은 중요한 일이다. 어떤 작업이 언제 끝날지를 예측할 수 있다면 보다 세밀한 계획이 가능해지기 때문이다. 이 때, 미래를 예측할 수 있는 가장 기본적인 방법은 과거 데이터를 기반으로 유사한 행동을 할 것이라고 하는 것이다. 때문에 시간에 걸쳐서 일정한 퍼포먼스를 보여줄수록 정확한 미래 예측이 가능하기 때문이다. 두 번째로는 UX, 즉 User Experience를 위해 중요하다. 만약 퍼포먼스가 일정하지 않은 스케줄러에 의해 작업이 관리된다고 하자. 버튼 반응이 처음에는 1초 뒤에, 다음에는 1분 뒤에 온다면 상당히 거슬릴 것이다.
2. Preemptive vs Non Preemptive
이제 스케줄러의 종류를 분류해보자. 분류 참 좋아해 만약 실행되고 있는 작업으로부터 자원을 뺏어오는 것이 가능하다면 우리는 해당 스케줄러를 Preemptive (선점 가능) 하다고 부른다. 이러한 것이 불가능하다면 Non Preemptive 하다고 한다.
Preemptive 스케줄러 (후술 P 스케줄러) 를 Non Preemptive 스케줄러 (후술 NP 스케줄러) 와 비교해보자. 만약 긴 작업이 실행되고 있는 도중에 우리가 웹 페이지의 버튼을 눌러 반응을 보려고 했다고 하자. 버튼 작업은 긴 작업에 비해 짧은 시간을 소모하지만, NP 스케줄러의 경우 그런거에 상관 없이 긴 작업이 끝날 때까지 버튼 반응은 오지 않는다. 버튼 작업이 현재 실행되고 있는 긴 작업의 자원을 뺏을 방법이 없기 때문이다. 이에 비해 P 스케줄러에서는 짧은 버튼 작업이 자원을 뺏어 먼저 수행된 뒤 종료되는 것이 가능하기 때문에 low latency를 가지고 response time이 짧아지며, 더 나은 UX를 제공한다.
물론 P 스케줄러도 단점이 있다. 어떤 작업이 실행될지는 스케줄러 마음대로이기 때문에 예측이 어렵고, NP 스케줄링보다 더 많은 Context Switching이 일어나기 때문에 이로 인한 overhead도 증가한다. NP 스케줄러에서의 Context Switching은 쓰레드가 의도적으로 자원을 놓는 yield나, 쓰레드가 종료되는 시점 뿐이어서 Context Switching이 최소화된다. 때문에 NP 스케줄러는 P 스케줄러보다 좋은 predictability와 좋은 퍼포먼스(throughput)를 가지게 된다. 이러한 특성 때문에 언제나 그런것은 아니지만, 서버에서는 NP 방식의 스케줄링을, 일반 PC에서는 P 방식의 스케줄링을 선호한다.

쓰레드의 생애 주기를 다시 살펴봤을 때, P 스케줄러의 경우 OS가 스케줄러를 활성화하는 시점은 다음의 5가지 경우다.
- Waiting -> Ready
- Running -> Waiting
- Running -> Ready
- New -> Ready
- Exit
이에 비해, NP 스케줄러에서는 다음의 3가지 경우에서만 OS에 의해 스케줄러가 활성화된다.
- Running -> Waiting
- Running -> Ready
- Exit
이는 Ready에 아무리 많은 작업이 대기중이어도 NP 스케줄러가 이를 신경쓰지 않는 점에서 기인한다.
3. Work Conserving vs Non Work Conserving
다음 분류로 Work Conserving 을 꼽을 수 있다. Work Conserving 한 스케줄러 (후술 WC 스케줄러) 는 실행될 수 있는 작업이 존재하는 한 자원을 항상 할당한다. 즉 작업이 존재할 때는 언제나 자원을 idle하게 두지 않는 것이다. 이렇지 않은 스케줄러는 Non Work Conserving (NWC) 스케줄러라고 한다. 사실 수업 때 NWC 예시도 말씀해 주셨는데 이해가 안되서 수록하지 않는다.
어쨋든 이들의 장단점을 분류하면 아래와 같은데,
| WC 스케줄러 | NWC 스케줄러 | |
| 자원 활용도 | Good | Poor |
| 퍼포먼스 | Better | Bad |
| Fairness | Poor | Better |
| Predictability | Bad (자원의 양과 상황에 따라 변동) | Good |
NWC를 NP와 같이하면 fairness와 predictability가 좋아지기 때문에, 자동차 등 해당 criteria가 중요한 시점에서 쓰인다.
수업에서는 해당 파트를 진행하면서 마지막으로 스케줄러가 여러 단계일 경우 어떻게 될 것 같은가에 대해 질문했다. 각각이 WC 방식과 NWC 방식을 채택할 수 있는데 이러면 종합적으로 WC 스케줄러일지, NWC 스케줄러일지 생각해보라고 했다. 내 의견으로는 하나라도 NWC가 끼어 있다면 종합적으로는 NWC가 될 것 같다. 모두 WC일 경우 그 결과는 자명히 WC일 것이고, 그 반대도 마찬가지일 것이다. 하나가 WC, 나머지가 NWC일 때는 실행해야 할 작업이 있음에도 자원이 남는 상황을 쉽게 생각할 수 있다. 때문에 해당 경우는 종합하여 NWC가 되는 것이다.
지금까지 P와 NP, WC와 NWC 방식의 스케줄러가 어떤 차이가 있는지 알아보았다. 어찌됐건 자주 쓰는 것은 P & WC인 스케줄러이며, 우리에게 익숙한 운영체제들 대부분 해당 방식을 채택하고 있다고 한다.
4. 스케줄러의 평가 척도
책에서 설명하는 정의하고 강의에서 나온 내용하고 달라서 볼 때마다 혼란스럽다. 제대로 정의하고 넘어간다.
- Throughput : 주어진 단위의 시간동안 얼마나 많은 작업을 끝낼 수 있는가? (# of jobs / time)
- Turnaround Time : 주어진 작업이 도착한 이후 얼마나 지나서 끝냈는가? (Finish Time - Arrival Time)
- Response Time : 주어진 작업이 도착한 이후 얼마나 지나서 처음 시작했는가? (First Executed Time - Arrival Time)
- Waiting Time : 주어진 작업이 Waiting과 Ready 상태로 보낸 총 시간
- Average Waiting Time : 전체 작업들의 Waiting Time의 평균
5. Uniprocessor에서의 Scheduling Policy
이제부터 스케줄링 policy에 대해 본격적으로 살펴보자. 가장 간단한 상황부터 가정해보자. 프로세서가 하나이고 작업 (쓰레드)가 여러 개인 상황에서 어떤 기준으로 작업을 실행할지(프로세서를 할당할지)를 결정해야 한다.
5-1. FIFO와 convoy 효과
가장 간단한 방법으로는 먼저 들어온 작업을 먼저 실행하는 선입선출(FIFO)의 방식을 채택하는 것이다. 이에 대한 예시로는 caching server가 있다고 한다. 이 방식은 간단하긴 하지만 문제가 있다. 만약 첫 번째로 도착한 작업이 실행 시간이 정말 오래 걸린다면?

Avg Throughput의 경우 3/30으로 초당 0.1개의 작업을 완료하며, Avg Turnaround Time은 (24 + 27 + 30) / 3 = 27, Avg Waiting Time은 (0 + 24 + 27) / 3 = 17이다. Avg Throughput은 바꿀 수 없다. 정해진 실행 시간이 있기 때문이다. 대신 ATT와 AWT는 바꿀 수 있다. 바로 실행 순서를 바꿔주는 것이다. 이렇게만 해줘도 눈에 띄는 개선을 보여준다.

이러면 ATT는 (3 + 6 + 30) / 3 = 13, AWT는 (0 + 3 + 6) / 3 = 3으로 개선된다. 우리가 여기서 배울 수 있는 교훈은 스케줄링 알고리즘을 개선하면 TT와 WT를 줄일 수 있다는 것이다.
앞서 살펴본 CPU 사용 시간이 긴 작업이 먼저 들어옴으로 인해 CPU 사용 시간이 짧은 작업들이 오래 기다려 전체적인 스케줄링 성능이 나빠지는 현상을 Convoy Effect라고 부른다. 마트에서 줄을 설 때 내가 계산할 것이 1~2개 정도로 적은데 앞 사람이 한 카트 째로 계산을 하고 있는 상황을 생각하면 이해가 쉬울 것이다. 이런 극단적인 경우가 실제로도 발생을 하기 때문에 문제가 된다.
일반적으로 작업은 CPU를 오래 사용해야 하는 CPU bound job과 I/O가 주를 이루어 CPU는 최소한으로 요구하는 I/O bound job로 분류할 수 있다. 일단 I/O bound job이라도 CPU에서 I/O를 요청해야 I/O를 처리할 수 있기 때문에 반드시 CPU를 요구한다. 이제 CPU bound job과 I/O bound job이 동시에 돌아가는 상황을 생각하자. CPU bound job이 먼저 실행되서 CPU를 점유하고 있는 시점에 I/O bound job은 짧게 CPU를 쓰고 I/O를 하러 갈 수 있는 상황에도 멀뚱하게 서서 기다릴 수 밖에 없는 상황이 발생한다. 그 동안 I/O device는 놀게 되므로(idle), I/O device 활용도가 떨어지게 된다.
5-2. SJF와 그 한계
그러면 이러한 치명적인 문제를 내포하는 FIFO를 좋게 만들 방법은 없을까? 앞서 설명한 것처럼 순서를 바꾸면 된다. 긴 작업이 먼저 실행되는 것으로 인해 문제가 생기는 것이므로, 언제나 가장 짧은 작업부터 먼저 실행하도록 하는 것이다. 이를 Shortest Job First (SJF), 또는 Shortest Remaining Time First (SRTF)라고 부른다. 앞서 살펴봤듯, SJF는 FIFO보다 TT와 WT가 좋아진다. 앞선 CPU bound, I/O bound 같은 경우에는 I/O가 실행되기 전에 CPU를 점유하는 시간이 짧은 순서대로 실행을 하도록 하는 것이다.
FIFO는 그 특성상 비선점 방식으로 운용되는 것과 비교해서 SJF는 선점 또는 비선점 두 가지 방식 모두 운용이 가능하다. 선점 방식일 경우 새롭게 들어온 작업의 전체 실행시간이 현재 실행되고 있는 작업의 남은 실행시간보다 짧을 경우 작업을 교체해서 실행하는 것이다. 이 때문에 선점 방식의 SJF가 비선점 방식의 SJF보다 response time이 작다. 선점 방식의 SJF는 또 특이한 점이, 바로 AWT를 최소화하는 것이 증명되어 있다는 것이다.
이러면 꽤나 좋은 스케줄링 policy 같은데 SJF는 그렇게 많이 채택되는 policy가 아니다. 이는 SJF에 치명적인 단점이 있기 때문이다. 첫 번째로, SJF는 모든 작업의 CPU burst time을 완벽하게 예측할 수 있어야 한다. 마치 마트 점원이 눈을 감고 어떤 손님부터 먼저 결제를 할 지 결정하는 격이다. 물론 앞서 설명했던 predictability가 보장된다면, Exponentially Weighted Average 같은 방식으로 과거의 burst time을 이용해 예측을 하는 방법이 있기는 하다.
그러나 위의 예지 문제를 차치하고서라도, 더욱 치명적인 점은 starvation, 기아 현상이 일어난다는 것이다. 기아 현상이란 특정 작업이 끊임없이 필요한 컴퓨터 자원을 가져오지 못하는 상황이다. SJF의 경우 끊임없이 짧은 작업이 계속 들어올 경우, 긴 작업은 계속 CPU를 할당받지 못한 상태로 대기할 수 밖에 없다. 이 때문에 SJF는 starvation이 일어날 때 ATT의 최소화 또한 보장하지 못한다고 한다.
5-3. Round Robin
SJF가 유발한 치명적인 문제는 특정 작업이 계속 실행되지 못하는 상태에 놓이는 기아 상태에 빠질 수 있다는 것이었다. 그래서 이를 해결하기 위해 Round Robin 방식의 스케줄링 policy를 개발하였다.
Round Robin에서 모든 작업은 일정한 정도의 시간 (time quantum 또는 time slice) 동안 자원을 할당 받는다. 만약 할당받은 시간 동안 작업을 끝내지 못한 경우, FIFO queue의 뒤로 가서 다시 시간을 할당받기를 기다린다. 만약 time quantum이 끝났을 때 자원을 차지할 다른 작업이 없다면 계속 실행된다. 이런 방식으로 각 작업이 한 번씩 실행되는 묶음의 간격을 Epoch라고 잡는다. Epoch를 기준으로 생각하면 각 Epoch 마다 현존하는 모든 작업이 한 번씩은 스케줄 될 기회를 갖기 때문에 기아 상태에 빠지는 작업이 없게 되어 starvation 문제가 해결된다. 참고로, time quantum을 일정하게 유지하여, idle한 상황이 발생할 경우, 해당 스케줄러는 NWC 방식이며, 작업이 끝나자마자 새로운 time quantum으로 다른 작업을 시작했다면 WC 방식의 스케줄러이다.
RR의 preemptiveness를 결정하는 사항은 한 프로세스가 본인에게 주어진 time quantum을 온전히 사용할 수 있는가의 여부로 나뉜다. 만약 한 time quantum을 진행하는 동안 새로운 프로세스가 개입하여 OS가 해당 프로세스를 실행할 수 있다면 preemptive한 것이며, 적어도 해당 time quantum이 끝나기 전에는 스케줄링 될 수 없다면 NP 방식이라고 할 수 있다.
Round Robin에서 time quantum의 길이를 선정하는 것은 핵심적인 사항이다. 너무 길면 FIFO랑 큰 차이가 없고, 너무 짧게 잡으면 Context Switching으로 인한 overhead로 인해 전체적인 성능이 저하된다. CPU의 레지스터를 저장하고 복원하는 시간, 가상 주소를 대체하는 시간, cache 변경으로 인한 miss rate 증가 등 Context Switching은 비용이 꽤 크기 때문에 너무 빈번한 Context Switching은 삼가해야 한다. time quantum의 길이를 잡는데 절대적인 기준은 없기 때문에 해당 사항은 OS 설계자가 신경써야 하는 부분이다. CPU bound job의 경우 긴 time slice를 선호하며, I/O bound job의 경우 짧은 time slice를 선호한다. 이는 스케줄된 시간에 최대한 작업을 많이 해야 하는 CPU bound job와 애초에 많은 CPU 시간이 필요하지 않아 짧은 Epoch를 기대하는 I/O bound job의 특성이 반영된 것이다.
지금까지 너무 Round Robin 칭찬만 한 것 같으니 RR 방식의 문제도 알아보고 가자. 정말 극단적인 가정으로 Context Switching에 들어가는 비용이 없다고 가정하자. 그럼 RR과 FIFO를 비교할 때 RR이 절대적으로 좋다고 할 수 있을까? 그렇지 않다. 같은 burst time을 가진 여러 작업을 실행한다고 할 때, RR의 경우 Response Time은 좋지만 모든 작업이 비슷한 Epoch 순환을 거쳐가는 것 때문에 끔찍한 TT를 가진다. 이에 비해 FIFO는 Response Time은 그저 그렇지만, TT가 모든 작업에 대해 나빠지지는 않는다. 이럼에도 FIFO에 비해 RR을 채택하는 이유는 Response Time이 좋다는 이유 하나 때문이다.
5-4. Max-Min Fairness
RR이 또 언제나 공평하다고도 얘기할 수 없다. RR은 비슷한 규모의 여러 작업들에 대해서는 나름 공평하다고 할 수 있으나, CPU bound와 I/O bound job들이 섞여있을 때에는 그렇게 공평하지 못하다. 만약 I/O bound job가 고유한 CPU를 가지고 있었다면 더 빨리 끝날 것을 다른 CPU bound job의 time quantum으로 인해 손해를 보고, 본인의 time quantum 은 다 쓰지도 못한 채 끝나는 경우가 있기 때문이다.
때문에 우리는 구체적으로 무엇이 "공평"한지 정의를 하고 이에 맞는 스케줄러를 생각해볼 필요가 있다. 무엇이 "공평"한가는 다소 의견이 갈릴 수 있으나, 스케줄링에서는 보편적으로 Max-Min Fairness를 공평의 척도로서 채택한다. 해당 방식은 작업에 할당될 최소 할당량을 최대화화는 것을 목표로 공평함을 달성하려고 한다.
예를 들어 10의 자원을 요구하는 4개의 작업이 {1.9, 2.5, 4, 5} 만큼의 자원을 요구한다고 하자. 모두 똑같이 자원을 분배하면 2.5씩의 자원이 돌아갈 것이다. 그런데, 첫 번째 작업은 1.9 만큼 밖에 요구하지 않으므로, 남는 자원 0.6을 나머지 작업에 똑같이 분배해 준다. 이러면 {1.9, 2.7, 2.7, 2.7}의 자원이 각각에게 돌아가는데, 두 번째 작업의 경우도 자원이 0.2만큼 남게 되므로 0.1씩을 나머지 작업에 분배한다. 최종적으로 분배는 {1.9, 2.5, 2.8, 2.8}이 되며 이렇게 되면 Max-Min Fairness가 충족되었다고 한다. 해당 Max-Min Fairness를 CPU & I/O bound가 섞여 있는 작업들에 적용하면 RR에서 유발된 문제를 해결할 수 있다. I/O bound job에 할당된 남는 시간은 앞선 방식대로 CPU bound jobs로 재분배해주면 공평한 양의 CPU 할당을 이뤄낼 수 있다.
RR은 이러한 측면에서 Max-Min Fairness를 달성하지는 않는다. Deficit RR 스케줄링이라고 provably Max-Min fair한 RR의 변형 알고리즘이 있긴 하지만 현 수업에서는 다루지 않을 것이다.
5-5. Priority Scheduling
다음으로 볼 것은 핀토스를 구현한 이들에게 익숙할 것인 priority scheduling이다. 각 작업마다 우선도를 지정한 뒤에, 가장 높은 우선도를 가진 작업에게 CPU를 준다. SJF에서는 expected remaining time이 우선도로서의 역할을 했다고도 생각할 수 있다. P 방식과 NP 방식 모두 채택할 수 있다.
우선도 스케줄링 또한 우선도가 낮은 작업이 있을 때 우선도가 높은 작업이 계속해서 들어올 경우 starvation이 발생한다는 문제점을 안고 있다. 다만, SJF와는 달리 해결할 수 있는 방법이 있다. 바로 시간이 지남에 따라 우선도를 점차 올려주는 것이다. SJF에서는 우선도가 예상 잔존 실행 시간이었기에 수정할 방법이 없었으나 일반적인 priority scheduling에서는 우선도는 조정할 수 있는 수치로 주어지니 작업이 대기할 동안 서서히 우선도를 상승시켜주면 언젠가는 실행될 것이라는 보장이 생긴다. 이러한 조정 과정을 aging이라고 한다.
5-6. MLFQ (Multi-level Feedback Queue)
이제 나머지 기초적인 스케줄링을 모두 봤으니 RR, FIFO, priority scheduling의 장점을 모두 계승할 수 있도록 만들어진 스케줄링 알고리즘인 MLFQ 방식을 살펴보도록 하자. MLFQ의 목적은 다음과 같다.
- Responsiveness. Run short tasks quickly, as in SJF.
- Low Overhead. Minimize the number of preemptions, as in FIFO, and minimize the time spent making scheduling decisions.
- Starvation-Freedom. All tasks should make progress, as in Round Robin.
- Background Tasks. Defer system maintenance tasks, such as disk defragmentation, so they do not interfere with user work.
- Fairness. Assign (non-background) processes approximately their max-min fair share of the processor.
MLFQ은 CPU bound job의 TT를 optimize하면서 I/O bound job의 RT를 최소화하는 것이 주된 목적이다. 이를 성취하려고 할 때 어려운 것은 주어진 작업의 종류나 다음 burst가 언제일지 등의 사전 지식이 없다는 것이다. 때문에, 과거에 어떻게 행동했는지를 바탕으로 작업의 priority를 변경하도록 하자.
MLFQ는 이름 그대로 여러 개의 Queue를 구현하여 각 Queue를 Round Robin 방식으로 운영한다. 각 Queue에 들어가는 작업들은 Queue 내에서는 동일한 우선도를 가지며, 높은 우선도의 Queue일수록 더 짧은 time slice가 배정된다. 스케줄러는 높은 우선도를 가진 작업을 먼저 선택하여 수행하며, 만약 정해진 time slice 동안 작업이 끝나지 않았다면 해당 작업의 우선도를 낮춰서 하위 Queue에 배치하도록 한다. 즉, 그림으로 표현하면 아래와 같은 형태가 된다.

모든 작업은 시작할 때 가장 높은 우선도를 가지고 시작하며, 긴 CPU 시간이 필요할수록 점차 우선도가 내려가면서 더 긴 time slice를 사용할 것이다. 만약 MLFQ의 time slice 할당이 반대로 높은 우선도에 긴 time slice를 주는 방식이었다면, RT를 최소화하려는 목적이 달성되지 않는다.
MLFQ의 특성에 의해 짧은 CPU burst time을 가지는 I/O bound job은 상위 Queue에 머무르려는 경향이 있으며, CPU bound는 하위 Queue에 머무르려고 할 것이다. 물론 아직 문제가 남아있다. priority를 사용하는 구조적 특성에 의해 I/O bound jobs가 계속 들어오면 CPU bound job에서 starvation이 일어날 것이므로, 틈틈이 priority boosting (aging) 보정 작업이 필요하다. 실제 운영 체제에서는 각 단계마다 충분한 양의 CPU를 할당받지 못한 작업들의 경우 우선도를 올려주어 적당한 양의 CPU 할당을 받도록 조정함으로서 starvation과 fairness 모두를 잡으려고 노력한다.
5-7. 스케줄링 policy 요점 정리
번역하기 귀찮다... 알아서 외우자..
- FIFO is simple and minimizes overhead.
- If tasks are variable in size, then FIFO can have very poor average waiting time.
- If tasks are equal in size, FIFO is optimal in terms of average waiting time.
- Considering only the processor, SJF is optimal in terms of average waiting time.
- SJF is pessimal in terms of variance in waiting time.
- If tasks are variable in size, Round Robin approximates SJF.
- If tasks are equal in size, Round Robin will have very poor average waiting time.
- Tasks that intermix processor and I/O benefit from SJF and can do poorly under Round Robin.
- Max-min fairness can improve waiting time for I/O-bound tasks.
- Round Robin and Max-min fairness both avoid starvation.
- By manipulating the assignment of tasks to priority queues, an MFQ scheduler can achieve a balance between responsiveness, low overhead, and fairness.
6. Multiprocessor에서의 Scheduling Policy
이제 다음으로 멀티 프로세서에서의 스케줄링을 살펴보자. 어떤 작업을 실행할지만 결정하면 됐었던 단일 프로세서의 경우와 달리 멀티 프로세서에서는 어떤 프로세서를 사용해서 선택된 작업을 실행할지도 결정해야 한다. 처음에 한 CPU에서 작업을 진행하다가 다른 CPU로 작업을 옮길 때에도 비용이 소모되므로, 결정을 잘 해야 한다.
가장 간단한 방법으로 모든 프로세서 사이에서 공유되는 global MFQ를 운영하면 어떻게 될까? 일단 여러 프로세서가 동시에 MFQ에 접근하는 상황이 일어나기 때문에 경합이 일어날 것이다. 때문에 동기화 문제를 잡기 위해 spinlock을 운용해야 한다. 또한 cache 사용이 효율적이지 않게 된다. 작업이 처음 실행이 됐었던 프로세서에 해당 작업이 다시 배정이 되리라는 보장이 없으며, 작업에 필요한 cache data는 기존 CPU에 위치해 있을 것이기 때문에 필요한 data를 다시 준비하는 데 필요한 시간이 낭비된다.
이러한 제약 사항을 극복하기 위해 per-processor ready list를 준비하는 것으로 수정한다. 각 프로세서마다 어떤 작업을 실행할지를 담아두는 ready list가 준비되어야 하며, WC 스케줄러의 경우 idle 한 프로세서가 다른 곳에서 작업을 가져오는 steal 기능도 마련되어야 한다. 물론 작업을 훔치는 것에도 경합이 있긴 하겠지만 모든 것을 global하게 운용하는 것에 비해 그 정도가 덜하다.

6-1. Affinity Scheduling
이제 각 프로세서는 고유한 ready list를 가지고 있다. 이를 가지고 처음 생각할 수 있는 것은 가장 간단한 방법으로는 쓰레드가 가장 최근에 실행되었던 프로세서의 ready list에 다시 넣는 것이다. 이러한 스케줄링을 Per-Processor Affinity Scheduling이라고 한다. 이러면 적어도 특정 작업이 여러 프로세서에 걸쳐서 실행됨에 의해 발생하는 cache 효율성 문제는 잡을 수 있다. cache hit이 증가하기 때문에 cache 활용도가 높아지는 것이다.

하지만 Affinity Scheduling은 문제를 가진다. 바로 parallel program을 처리하지 못한다는 것이다. parallel programming이란 복수의 컴퓨팅 자원의 이점을 활용하기 위해 한 작업을 여러 개의 작은 작업으로 나누어 동시에 여러 연산을 하는 것이다. 이를 Affinity Scheduling 대로만 처리한다면 같은 프로세서에서만 처리될 것이기 때문에 전혀 병렬 처리가 되지 않는다. 이는 아래 그림과 같은 Bulk Synchronous Patern (BSP) 같이 한 작업만 지연되더라도 나머지 모든 작업이 지연되는 상황에는 적합하지 못하다.
6-2. Gang Scheduling
이 문제를 잡기 위해 새로운 스케줄링 방식인 Gang Scheduling을 도입한다. Gang Scheduling은 연관된 쓰레드의 집합이 여러 프로세서에 걸쳐서 동시에 실행될 수 있도록 스케줄링한다. 단일 프로세스에 속한 쓰레드들이 동시에 스케줄링되면서 동기화 보류와 이로 인해 파생되는 Context Switching으로 발생하는 overhead를 잡을 수 있다. 모든 CPU의 스케줄링은 동기적으로 이루어지며, 아래 그림은 Gang Scheduling이 이루어지는 방식을 표현한 것이다.
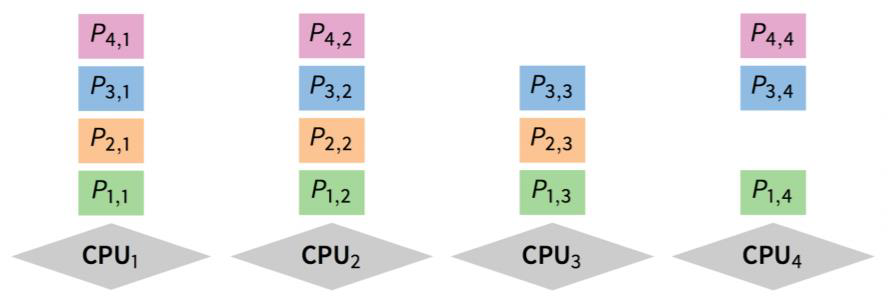
그림에서 CPU4가 idle한 것을 보면 알 수 있듯, Gang 스케줄링은 NWC 스케줄링이다. 일부 CPU 자원이 남는다고 해도 그 수가 다음 작업을 수행하기에 충분하지 않다면 CPU가 idle하게 둔다. 일부 작업을 미리 하더라도 어차피 다른 작업이 수행될 때까지 대기하는 문제가 발생할 수 있기 때문이다.
'코딩 삽질 > OS 요약 정리' 카테고리의 다른 글
| (22.04.11 ~ 04.13) Concurrency Bugs (0) | 2022.04.13 |
|---|---|
| (22.04.11) Synchronization (0) | 2022.04.11 |
| (2022.04.09) Concurrency and thread (0) | 2022.04.09 |
| (2022.04.09) Programming Interface (0) | 2022.04.09 |
| (2022.04.09) Kernel Abstraction (2) (0) | 2022.04.09 |



