
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 핀토스 프로젝트
- 제발흰박
- alarm clock
- 아직도 실험 중
- botw
- 글리치
- Project 1
- 바빠지나?
- 일지 시작한 지 얼마나 됐다고
- 황금 장미
- 가테
- 핀토스 프로젝트 3
- 끝
- 노가다
- multi-oom
- 핀토스 프로젝트 1
- 자 이제 시작이야
- 셋업
- PINTOS
- 글루민
- 마일섬
- 파란 장미
- 내일부터
- 핀토스 프로젝트 2
- 핀토스 프로젝트 4
- Today
- Total
거북이의 쉼터
(2022.05.30) File System (1) 본문
지금까지 해왔던 것들을 다시 정리하고 가자. 우리는 지금까지 CPU 쪽에서 인터럽트, 스케줄러, 프로세스와 쓰레드 abstraction을 배웠고, 메모리 쪽에서는 MMU, VM, PM, eviction policy, TLB 등을 배웠다. 이제는 IO 파트에 위치한 abstraction만 공부하면 전체 컴퓨터와 관련된 것을 공부한 것이 된다. 네트워크와 관련된 것은 네트워크 수업 때 배워라.
앞으로 할 포스팅의 주 주제는 file system이 될 것이다. Physical device상에서 어떤 것이 유용한 abstraction이 될 지 생각할 것이다. 그 뒤에는 디스크나 플래시 메모리 같은 스토리지 HW의 특성을 배울 것이다. 마지막으로는 파일 시스템을 사용하는 어플리케이션의 패턴을 이용해 메커니즘을 설계하는 방식을 생각할 것이다.
파일 시스템은 persistent storage상의 abstraction을 제공한다. 이러한 abstraction으로는 storage에 data를 작성할 때 사용되는 API인 파일을 들 수 있다. Device는 머신이 crash 되더라도 대게 정보를 보존하는 storage를 제공하며, block level의 random access를 할 수 있다. 메모리는 byte 단위의 access가 되는 것과 비교할 수 있다. 싼 값에 큰 저장용량을 제공하지만 상대적으로 느린 퍼포먼스를 보여준다.
새로운 Abstraction에 대한 analogy를 살펴보자. Virtual Memory는 Physical Memory의 abstraction이며, level of indirection (abstraction layer에서 real layer로의 변환)은 virtual address에서 페이지 테이블을 통해 physical address로 가는 것이었다. 이와 유사하게 파일 시스템에서도 분석해보면 파일은 storage의 abstraction이며, level of indirection은 이름과 오프셋이 indexing mechanism을 통해 스토리지의 특정 block address로 연동되는 것이다. 이러한 측면에서 볼 때 고단계에서는 두 abstraction이 비슷하다고도 볼 수 있지만 내부 구현을 자세히 살펴보면 극명히 달라지는 것을 볼 수 있다.
storage의 abstraction은 파일과 디렉토리로 나눌 수 있다. 파일은 persistent storage에 기록된 연관된 데이터를 하나의 이름아래 모아놓은 집합으로서, 각 파일은 내부 파일 ID로 기능하는 inode number를 가진다. Inode는 하나의 파일 시스템 내에서 고유하다. 리눅스에서는 파일 시스템이 VFS layer와 EXT4라는 layer으로 분리되어 있다. 그래서 abstraction of file은 VFS에, inode의 구체적인 연산은 EXT4에 구현되어 있다. 윈도우 등 여러 OS가 이 방식을 채택하는데, 이러한 방식을 채택하는 이유는 VFS 아래에 깔릴 수 있는 파일 시스템의 종류가 다양하기 때문이다. 전세계에 존재하는 파일 시스템은 약 900개 정도로, 리눅스에만 60 종류가 존재하고, 파일과 오프셋을 디바이스로 매핑하는 방식은 각 시스템마다 다르다. 이를 가능하게 하는 inode 포맷 또한 다르기 때문에 VFS는 파일 시스템의 implementation detail을 가리는 abstraction이라고 볼 수 있다. 그래서 하위 파일 시스템에는 파일을 다루는 코드가 일절 등장하지 않는다. 이는 VFS에서 다루는 개념이기 때문이다. 다음으로 디렉토리는 파일들을 정리하는 방식을 제공하며, 디렉토리 자체도 파일의 일종이다. 내용으로는 유저가 익숙한 파일 이름을 inode number로 매핑시키는 리스트를 들고 있으며, 디렉토리가 디렉토리의 하위 디렉토리로서 위치하여 계층 구조의 디렉토리 트리를 형성할 수 있다. 디렉토리는 file name to inode number의 abstraction이라고 볼 수 있다.
파일 시스템을 디자인함에 있어 주요한 3가지 측면을 살펴보자.
1) Naming
이는 어떻게 file 이름과 연관된 데이터 블록을 찾아낼 것인가를 의미한다. 또한 메모리에서 데이터를 처리할때는 바이트 단위로 연산이 일어나는데에 비해 디바이스에서는 블록 단위로 처리가 일어나기 때문에 이러한 간극을 메꾸는 방법을 배울 것이다. 메모리는 바이트 단위 연산이 일어날 수 있었기 때문에 이러한 요구사항이 없었다.
2) Performance
파일 시스템은 DRAM에 비해 속도가 느리기 때문에 파일의 데이터와 메타데이터를 DRAM에 cache에 저장하여 사용한다면 속도 향상을 기대할 수 있다. 해당 cache가 가득 찼을 때 어떤 data를 storage로 evict할지 결정하는 문제는 이전에 다루었던 문제와 비슷하다.
3) Persistency
업데이트 도중 crash가 나거나, disk가 어떠한 이유에서는 corrupt가 되었을 때에도 데이터가 파일 시스템에 정상적으로 잔류해 있을 수 있는지를 평가한다. 메모리는 해당 요소가 필요가 없었기에 이 또한 파일 시스템만이 고려해야할 독특한 문제이다.
본격적인 디자인을 하기 전에 디바이스의 abstraction을 살펴본다. 파일 시스템이 디바이스와 어떻게 소통하는지를 알아야 디자인이 수월할 것이다. 대부분의 storage device는 host system과 연결되는 3가지 인터페이스를 가진다. Status, Command, Data이다. Status check를 위해 취할 수 있는 방식은 두 가지가 있다. 이전에 배웠던 polling과 인터럽트가 이것이다. Data transfer을 위한 방법도 두 가지가 있는데, 하나는 DMA이고 다른 하나는 Programmed IO (in, out 명령어를 통한 방식)이다. in 명령어를 사용하면 해당 명령어를 사용한 시스템이 일시적으로 중단되고, 디바이스는 해당 명령을 처리하면서 데이터 transfer가 일어난다. 이 때문에 PIO의 대부분은 synchronous transfer using CPU로 사용된다. DMA는 이와 반대로 CPU가 관여하지 않고 디바이스가 자체적으로 알아서 데이터 transfer를 하면서 작업이 끝나면 CPU가 알아차리는 방식이다. Control은 위의 data transfer을 issue하는 방법을 나타낸 것으로 이 Command를 보내는 것도 두 가지 방식이 있다. 위에서 소개된 in, out같은 특별한 명령어를 사용하는 방법과, Memory mapped IO가 있다. 메모리의 특정 구역을 파일을 매핑해서 사용하겠다고 선언하면 해당 메모리 영역에서 일어난 변화가 command로서 디바이스에 통보되는 방식이다. 현재 사용되는 가장 흔한 방식은 DMA와 Memory Mapped IO를 엮어서 사용하는 방식이며, polling과 인터럽트는 용도에 맞게 사용된다. 퍼포먼스 용도로는 polling이 더 빠르기 때문에 polling을 사용하지만, CPU cycle을 잡아먹기 때문에 흔히 사용하지는 않고 high performance NIC와 storage에 사용되는 편이다.
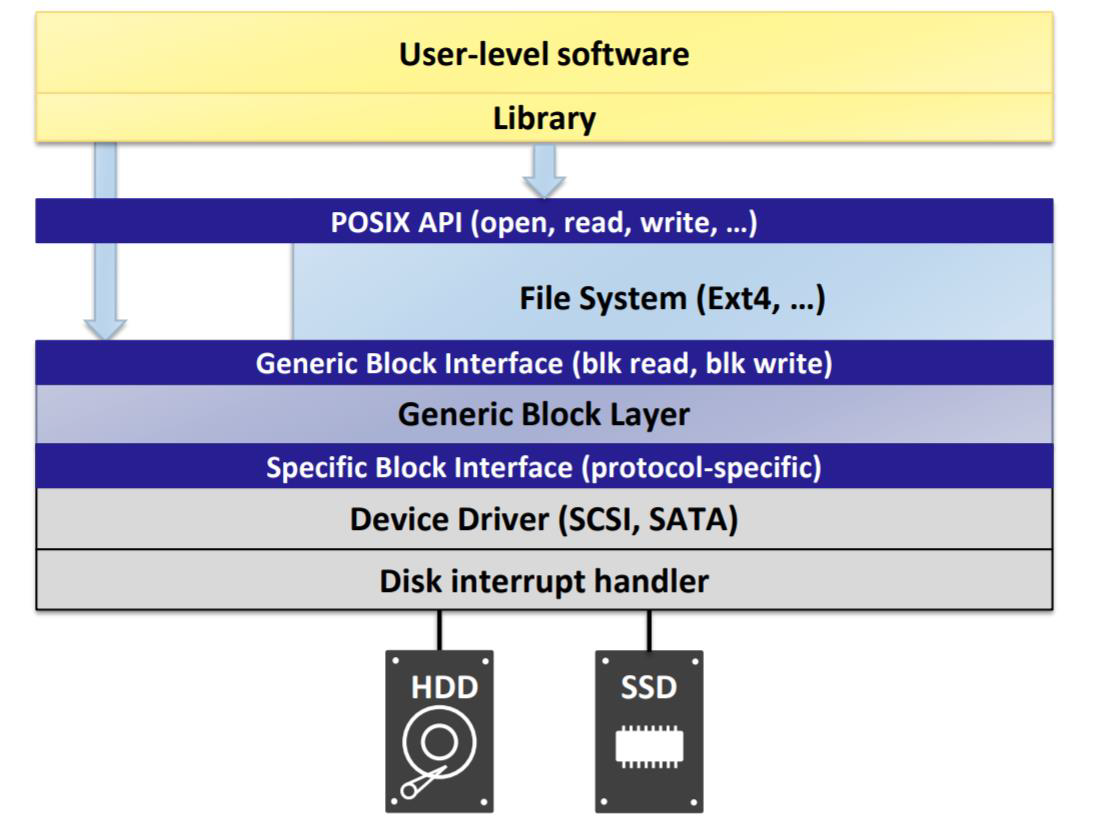
위의 그림은 리눅스의 파일 시스템 계층을 나타낸 것이다. libc 라이브러리는 open, read, write등을 사용하기 위한 system call을 제공하며, open, read, write는 POSIX API로서 VFS에 구현되어 있다. 그 세부적인 사항은 하위 파일 시스템에 구현된다. 읽고 쓸 block address를 구했다면, 파일 시스템은 General Block Layer에 해당 블럭과 관련된 작업을 진행할 것을 요청한다. Block Layer는 디바이스에 대한 abstraction이 이뤄져 있기에 디바이스의 종류는 신경쓰지 않고 블럭에 대한 작업을 진행한다. Block Layer는 다시 Specific Block Interface로 요청을 보냄으로서 각 종류의 디스크 드라이버가 해당 요청을 끝내 받아 그 종류별로 필요한 작업을 진행한다. 우리가 앞으로의 강의에서 배울 것은 VFS와 파일 시스템 계층에 해당하는 내용으로 그 하위 계층은 다루지 않을 것이다.
file descriptor(fd)는 파일의 id를 나타내는 것으로, 파일이 VFS에 구현되어있는 abstraction이므로 이 또한 VFS에 구현된 사항이다. 따라서 파일 디스크립션 테이블 또한 VFS layer에 위치해야 한다.
파일시스템은 예로부터 OS의 가장 어려운 부분이었고, OS의 단일 주제를 다루는 논문들의 주제 중에서 FS가 다른 주제에 비해 더 많은 것을 확인할 수 있다. 파일 시스템의 주요한 과제는 다음과 같은 것들이 있다.
- Don't go away (ever)
- Associate bytes with name (files)
- Associate names with each other (directories)
- Can implement file systems on disk, over network, in memory, in non-volatile ram, on tape
어디에든 구현할 수 있는 것이 파일 시스템이지만 우선 디스크에 구현하는 것에 주목하고 후에 확장하도록 한다. 막간으로 디스크와 메모리를 비교하면 아래와 같다.
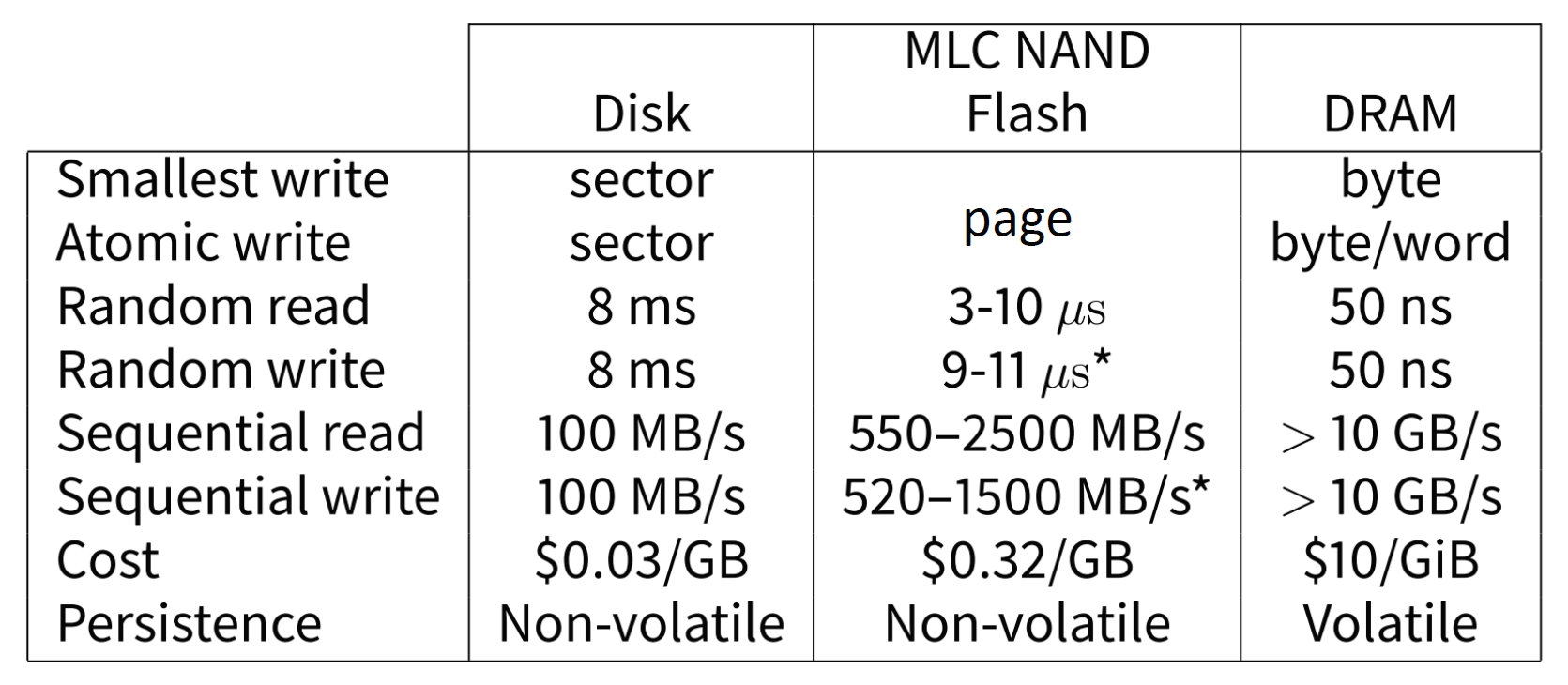
이전에는 주로 512B 크기의 섹터가 디스크에 쓰는 최소단위였지만 요즘은 주로 4kB의 크기를 사용한다. 플래시 메모리에서는 벤더마다 다른 크기인 "페이지" 단위를 최소단위로 한다. 디스크는 read에 ms 단위가, 플래시는 마이크로 s, DRAM은 나노급의 시간이 들어간다. 현재 디스크의 Sequential Read는 throoughput은 좋으면 200MB/s 정도이며 DRAM의 경우 각각 100 GB/s 정도의 속도를 나타낸다. 디스크는 DRAM이나 플래시보다 값이 싸며, 표에 나온 것 이외에도 NVMEM이나 low latency SSP등 여러 저장장치 계층 구조가 있다.
위에서 비교한 것처럼 디스크의 쓰기 단위는 섹터였다. 그러나 우리는 일상적으로 파일에 바이트 단위로 write하기를 바란다. 이 때문에 파일의 한 바이트를 update하기 위해서는 해당 바이트를 포함하는 섹터를 읽은 뒤, 그 바이트만 변경하고 전체 섹터를 다시 디스크에 쓰는 "Read-Modify-Write" 방식이 요구된다. 만약 write하려는 block이 cache되어 있다면 read in과정은 불필요하다. 섹터는 atomicity의 단위이기도 하기에 도중에 crash가 나는 일이 있더라도 섹터 도중에 write가 끊이는 일은 일어나지 않으며, 여러 개의 섹터를 작성하는 도중에 crash가 난 경우라면 섹터 단위로 끊기게 된다. 이러한 특징이 consistency의 root cause가 된다.
지금까지 알아야 할 기초 지식들을 전부 배웠다. 이제 파일을 좀더 깊게 보자. 파일은 이름이 붙은 디스크 내의 바이트이다. 유저의 입장에서는 named sequence of byte라고 할 수 있지만, 파일 시스템이 보기에 파일은 디스크 블록들의 집합이라고 할 수 있다. 파일 시스템의 역할은 유저에게 익숙한 이름과 오프셋을 디스크 블록으로 매핑시키는 것이다. 파일 시스템 API로는 파일을 생성, 삭제하고, 파일에 읽고 쓰는 작업을 포함한다.
파일 시스템 디자인에서 삼을 목표는 다음과 같다.
- Performance : 작업은 최대한 적은 수의 디스크 접근으로 이루어져야 한다.
- Space Efficiency : space overhead를 최대한 적게 가질 것 (연관된 것들은 group지어 관리하기)
- 하위 디바이스의 특징을 고려할 것
페이지 테이블이 가상 페이지를 물리 페이지로 매핑하듯, inode라 불리는 파일의 메타데이터는 파일의 byte offset을 disk block 주소로 매핑하며, 디렉토리는 파일의 이름을 해당 파일의 disk address나 file #로 매핑한다.
파일 시스템의 Workload를 보면, 파일 시스템에서 대부분의 파일은 작은 크기의 파일들이지만 스토리지 용량에 주로 기여하는 것은 큰 크기의 파일들이다. 이러한 특징은 storage space를 관리하는데 사용할 수 있는 특성이다. 마찬가지로, 대부분의 파일 access는 작은 파일들에서 발생하지만, 전체 IO bytes의 양에 더 많이 기여하는 것은 큰 파일들이다. 이는 좋은 performance를 이루기 위해 사용될 수 있는 정보이다. 그 외에 파일이 사용되는 방식은 아래와 같다.
- 대부분의 파일은 순차적으로 read/write 된다.
- 몇몇 파일은 랜덤하게 read/write 될 수 있다. (database file, swap file)
- 몇몇 파일은 생성될 때 고정된 크기로 생성되고, 몇몇 파일은 작게 생성돼서 점차 자란다.
이러한 점을 고려하면서 파일 시스템 디자인을 해 보자.
작은 파일을 위해서는 작은 블록 크기가 이상적이다. 블록이 너무 커지면 internal fragmentation이 발생하여 디스크 공간이 낭비될 것이다. 같이 사용되는 파일은 같이 저장되어야 하고, 이는 디렉토리로서 관리된다. 작은 파일에게는 메타 데이터 크기가 영향을 미친다. 파일에 데이터를 쓸 때 메타 데이터에도 접근하기 때문이다. 쓰려는 바이트 수보다 메타 데이터의 크기가 지나치게 크다면 비효율적일 것이다. (IO for metadata & IO for data)이 때문에 메타 데이터는 최대한 압축된 형태로 존재해야 한다.
큰 파일을 위해서는 블록이 너무 자잘하게 쪼개진다면 비효율적일 수 있다. 스토리지 효율을 위해 어느 정도 큰 사이즈의 블록을 요구한다. Sequential Access를 위해 Contiguous Allocation이 요구되는데, 이는 spatial locality 때문이다. (prefetch 요구) 때때로 필요한 random access를 위해 efficient lookup 또한 요구한다. 파일 생성시에는 해당 파일이 작을지, 클지 알수 없다. 파일이 영구적일지 임시적일지도 알 수 없으며, 파일이 순차적으로 접근될지, random하게 접근될지 알 수 없다. 이러한 특징을 모두 커버할 수 있는 디자인이 필요하다.
익숙한 파일 시스템 API를 살펴보고 가자.

이 중 fsync는 이전에도 언급한적이 있다. fsync는 DRAM에 cache된 파일에서 일어난 변화를 디스크로 강제로 반영되도록 한다.
파일 시스템의 내부에서 파일의 이름을 주면 파일의 데이터로 변환하는 과정은 아래와 같다.
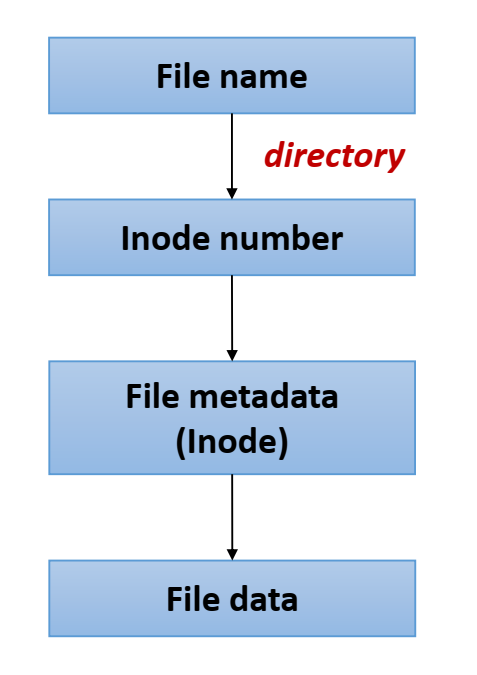
/a/b를 찾는다고 할 때, directory walk를 통해 /a 디렉토리 정보 안의 b와 매칭되는 directory entry를 찾아 inode number를 찾아낸다. inode number를 이용해 inode를 찾아 읽으므로서 파일의 메타 데이터를 알 수 있다. 파일의 메타 데이터 내부에는 오프셋을 원하는 정보가 들어있는 파일 데이터의 블록의 위치로 변환할 수 있는 구조가 있다. 이를 이용해 파일의 실제 데이터에 접근하는 것이다.
파일은 sequence of bytes로 파일 시스템은 그 정보가 무엇인지는 신경쓰지 않는다. 파일 시스템에게 중요한 것은 파일의 attribute(메타 정보), 즉 파일의 크기, 파일을 구성하는 블록의 위치, 파일의 소유자와 접근 권한, 타임 스탬프 등이다. 특히 block locations 없이는 파일의 실제 데이터를 찾을 수 없기 때문에 매핑 information은 inode에 수록되어 디스크에 저장되어 있어야 한다.
디자인을 할 때 주요한 쟁점은 다음과 같다.
- Index Structure : 어떻게 파일에 속하는 블럭을 찾을 것인가?
- Index Granularity : 블럭의 사이즈는 어떻게 할 것인가?
- Free Space : 디스크 내의 미사용된 블럭을 어떻게 찾을 것인가?
- Locality : Spatial Locality를 어떻게 보존할 것인가?
- Reliabilty : 머신이 파일 시스템 연산 도중에 크래시 날 경우 consistency를 어떻게 보장할 수 있는가?
앞으로 다룰 주제들을 배우면서 이 질문들에 답하게 될 것이다.
Index Structure
이제부터 파일 이름이 파일 데이터로 변환되는 과정 중 inode에서 offset을 필요한 파일 데이터 블록의 위치로 변환하는 index structure를 살펴볼 것이다. 파일 시스템은 파일 오프셋을 블럭으로 번역해주는 주체가 메모리처럼 HW가 아니다. 해당 작업은 순수히 SW단에서 일어나는 과정이며, 이는 DRAM과 달리 디스크의 속도가 매우 느려 굳이 HW로 구현할 필요가 없기 때문이다. 이 점으로 인해 index structure는 온전히 SW로만 구현되어 있다. Index Structure를 디자인하는 것도 여러 방식이 존재한다.
Linked Files
index structure를 linked list처럼 구현한 방식이다. file의 첫 번째 블록부터 시작해서 각 블록에 다음 블록으로 연결되는 포인터를 둔다. 파일의 메타 데이터는 파일의 첫 번째 데이터 블록의 포인터를 가지고 있게 한다. 간단하고, 구현하기도 쉬워 널리 사용된다.
File Table (FAT)
모든 파일은 블록의 linked list로 생각하되, linked file에서처럼 블록 내에 다음 블록의 정보를 저장하는 것이 아닌, 디스크의 일정 영역을 할당해 해당 부분에 모든 블록의 연결 관계를 기록한다. FAT도 이런 방식으로 구현된 index structure이다. FAT는 블록 넘버에 해당하는 엔트리에 다음 블록이 어떤 넘버를 가지고 있는지를 기록함으로 연결 관계를 가지고 있다. OS는 파일의 크기를 알고, 블록의 크기 또한 알고 있기 때문에 파일이 몇 개의 블록으로 구성되는지 알 수 있다. 해당 제한 내에서 어느 정도를 타고 들어가면 원하는 오프셋에 해당하는 블록이 나오는지 계산할 수 있고, 이는 테이블에 기록된 연결 관계로 타고 들어간다.

Linked File과 마찬가지로 연결된 포인터를 따라가는 것은 똑같지만, Linked File에서는 연결된 관계를 파악하기 위해 필요없는 데이터 블록까지 DRAM에 읽어와야 했던 것과 달리 FAT는 테이블만 DRAM에 올려 놓으면 어떤 파일이든 연결 관계를 파악할 수 있기 때문에 더 효율적이다. FAT의 장점은 할당되지 않은 free 블럭을 쉽게 찾을 수 있고, 파일 끝에 내용을 append하고 파일을 지우는 것이 쉽다는 것이다. FAT의 치명적인 단점은 random access가 매우 느리다는 것이다. 어찌됐건 원하는 지점까지 가려면 traverse가 수반되기 때문이다. 파일을 삭제할 때 OS는 블록을 zero-out하지 않는다. 이는 메타 데이터를 지워버려서 연관된 데이터 블록에 접근하지 못하게 하는 것이 같은 효과를 내면서 더 효율적이기 때문이다. 이 때문에 지워진 파일을 복구하는 것이 가능한 것이다.
Indexed Files
FAT의 random access가 느린 단점을 보완하기 위해 새로운 방식의 index structure를 도입했다. 파일의 메타 데이터에 데이터 블럭을 가리키는 포인터를 모아놓은 array를 저장하는 것이다. 물론 VM 처럼 array를 통짜로 심어 놓으면 큰 파일에 대해서는 파일의 메타 데이터가 겉잡을 수 없이 커질 것이다. inode가 기본적으로 너무 커지면 작은 파일에 대해서는 비효율적이기 때문에 12개의 data pointer 밖에 들고 있을 수 없다. 블록의 사이즈가 4kB라면 최대 크기는 48kB가 되는 것이다. 이러한 제약을 극복하기 위해 indirect block pointer를 둔다. VM에서의 페이지 테이블 처럼 트리로서 포인터를 담고 있는 블럭을 관리하는 것이다.
Multi-level Indexed Files
해당 방식은 Indexed Files를 발전시켜 더 많은 데이터 포인터를 들고있게 하는 방식이다. inode에는 15개의 block pointer와 더불어 부가적인 것들이 추가된다. 아래 그림과 같이 12개는 위처럼 direct block으로서 사용되지만 1개는 single indirect, 1개는 double indirect, 마지막 1개는 triple indirect pointer로 사용된다. indirect block pointer를 사용해서 inode는 작게 유지하되 큰 파일을 유지할 수 있는 것이다.
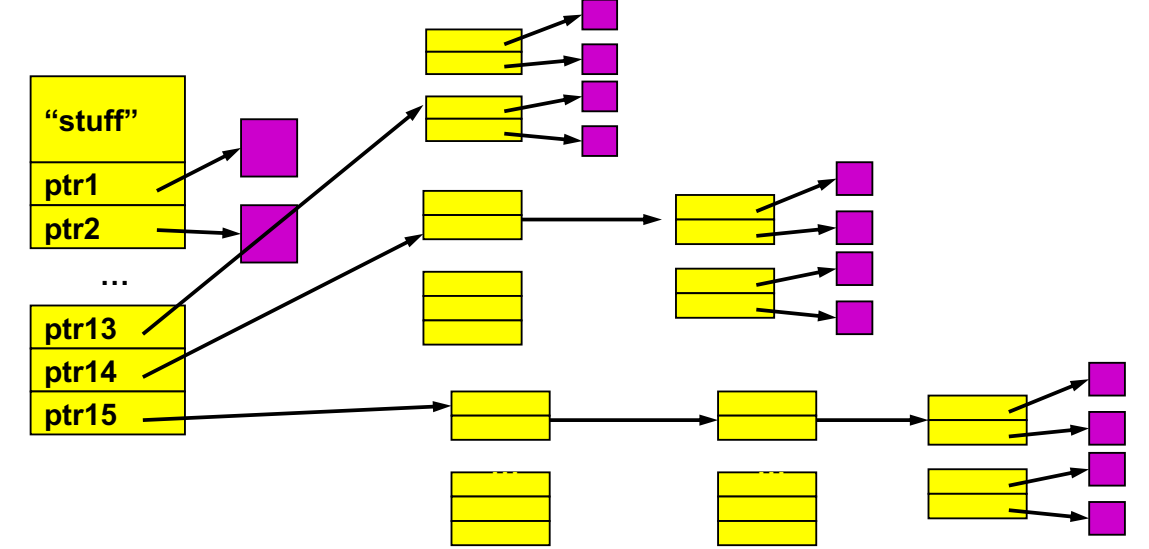
FFS (fast file system) 이 해당 방식을 사용해서 index structure를 구현한다. indirect block pointer가 가리키는 블록의 크기가 4kB이고 해당 블록 내의 block pointer의 크기는 4B라고 하면 1K의 엔트리가 있는 셈이므로 각각이 4kB의 블록을 가르켜 총 4MB의 추가 데이터를 저장할 수 있는 것이다. double 레벨과 triple 레벨도 같은 방식으로 계산하면 1K씩 곱해지기 때문에 4GB, 4TB가 된다. 해당 방식을 위해 indirect block 또한 유지가 필요하다는 특징이 있다.
Sequential Read를 할 때는 작은 범위에 대해서는 DP를 먼저 순회하고, 그 이후부터는 DFS를 하듯 indirect block을 순회하고, doubly indirect block을 순회하고, triple direct block을 순회하는 방식으로 진행한다. 이 방식은 Random Access 또한 빠르게 할 수 있다. Sequential Search 없이 Random Access를 위해서는 offset의 범위를 우선 보고, 어디 있을지를 알 수 있다. 예를 들어 48kB 이내라면 direct block 중에 있을 것이고, 4MB 이내 48kB 초과라면 indirect block일 것이다. offset을 이용하면 구체적으로 어떤 pointer를 따라가야 하는지도 계산할 수 있으므로 random access를 빠르게 할 수 있는 것이다. 더 복잡한 구조도 있긴 하지만 index structure는 여기까지 보도록 하자.
파일과 디렉토리는 모두 inode로 매핑되기 때문에 inode는 자신을 가리키는 주체가 file인지 directory인지 나타내는 정보를 들고 있다. 이외에도 owner(uid)와, 작업 권한(rwx), 크기(in bytes), 사용하는 block의 개수, access time, create time, link 카운트를 갖고 있으며, 나머지는 위에서 살펴본 index structure가 차지하고 있다. 핀토스는 이보다 간단하게 구현되어 있다. KAIST 버전의 핀토스는 FAT를 사용해서 구현되어 있다.
inode는 storage내의 fixed size array에 위치하고 있으며, 디스크가 초기화될 때 해당 array의 크기가 결정되어 변하지 않는다. inode의 집합은 디스크의 한 영역을 차지하고 있고, 해당 위치의 시작점은 super block이 가르키고 있다. (다음 포스팅에서 구체적인 내용을 살펴볼 것이다) inode가 inode array내에서 가지는 index를 inode number, 또는 i-number라고 하며, OS는 파일을 i-number로 참조하게 된다. 파일이 open되면 해당하는 inode가 메모리로 불러와진다. 파일의 내용이 바뀌어 inode가 바뀌게 되면 해당 내용은 후에 디스크에 반영이 되기 위해 written back된다.
지금까지 작은 파일과 큰 파일이 어떻게 저장되는지를 살펴보았다. 그럼 중간에 공간이 뚤린, Sparse File을 살펴보자. Virtual Space에서 모든 가상 주소 공간에 해당하는 프레임이 할당되지 않은 것처럼, 일부 구역은 사용하고, 일부 구역은 block이 할당조차 되지 않게 하는 것이다. indexed file 방식 (indirect indexing)에서는 sparse file을 간단히 만들 수 있다. 그러나 기본적인 FAT에서는 sparse file을 만드는 것이 불가능하다. 애초에 random access 조차도 sequential search를 통해 타고 들어가야만 하기 때문에 중간 block이 반드시 할당되어 있어야 한다.
inode number에서 inode data를 가져오는 방법은 inode array 내부에서 가져오는 것이다. inode data에서 data를 가져오는 방법은 FAT와 indirect indexing 등의 index structure를 통해서였다. 이제 파일 이름을 inode number로만 변환할 수 있으면 모든 것이 완성된다. 그러니 이 단계에 해당하는 디렉토리를 보도록 하자. 지금까지 줄지차게 말해왔듯, 디렉토리 자체도 파일이다. 디렉토리는 일반적인 유저 데이터를 담고 있는 것이 아닌 파일의 이름과 파일의 inode number를 연결하는 정보를 담고 있다(name - inode number pair). 디렉토리는 재귀적으로 존재할 수 있어, 특정 경로의 파일을 찾기 위해서는 file lookup, 또는 directory traverse가 필요하다. 예를 들어 /home/tom/foo.txt를 찾고자 한다. 먼저 root directory를 읽어야 하므로 root directory에 해당하는 inode를 읽는다. root directory에 해당하는 inode 위치는 대게 고정되어 있기에 root directory의 데이터를 가져올 수 있다. 해당 정보를 읽었더니 home의 inode number가 158이라면, inode table 내에서 해당하는 inode를 가져와 데이터를 가져온다. home 또한 directory이기에 home의 데이터를 가져오면 또다시 name - i-number pair가 있을 것이다. 만약 해당 데이터 내의 tom이 830 i-number를 가지고 있다면 비슷한 과정이 일어나 tom의 디렉토리 데이터를 가져온다. tom 내의 foo.txt와 매칭되는 pair를 찾으면 최종적으로 원하는 파일의 inode number를 가져올 수 있다.
디렉토리는 정확히 내부적으로 어떻게 구현되어있는지 살펴보자.
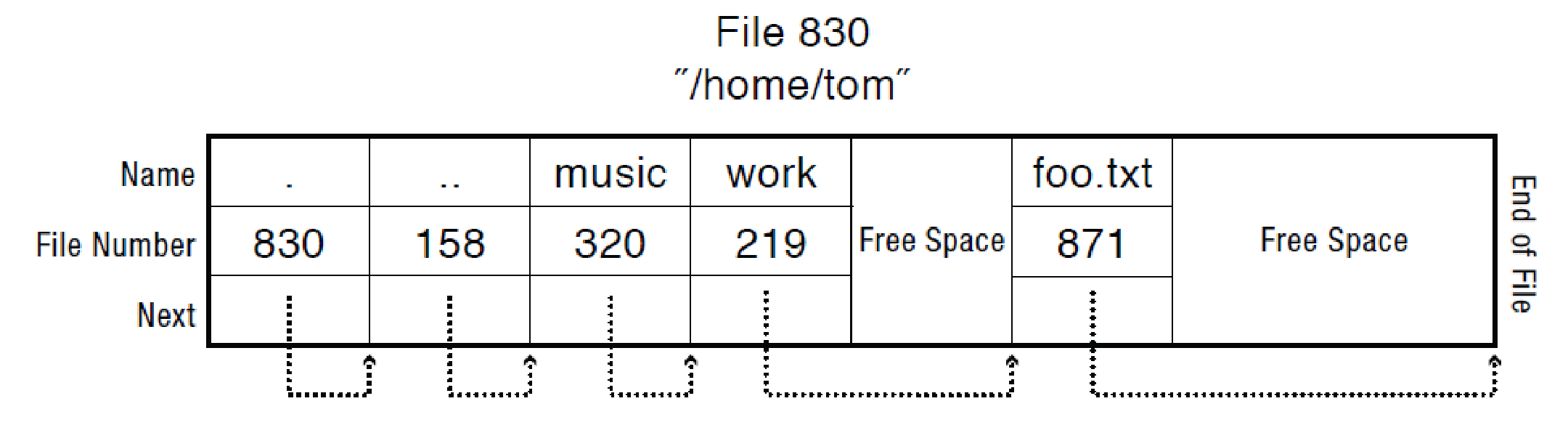
필요한 파일 이름을 찾기 위해서는 linear search가 이루어진다. 그림에서 .은 현재 디렉토리, ..은 부모 디렉토리를 의미한다. 디렉토리에서 각 엔트리는 next pointer를 가지고 있어 원하는 파일 이름을 발견할 때까지 순회할 수 있다. 해당 방식은 파일 개수가 적은 디렉토리에는 문제가 없는 방식이지만 정말 많은 수의 파일이 있다면 선형 탐색만으로는 굉장히 비효율적인 방식이 된다. 그래서 큰 디렉토리에 대해서는 B+ 트리로 구현이 되어있기도 한다. B 트리와 B+ 트리의 차이는 B+ 트리에는 최하위 레벨의 리프노드에 데이터가 모두 모여있어, internal node가 inclusive하다는 점이다. 그림과 같이 B 트리에는 5가 리프 노드가 아닌 위치에만 존재하지만 B+ 트리에서는 리프 노드에도 존재한다.
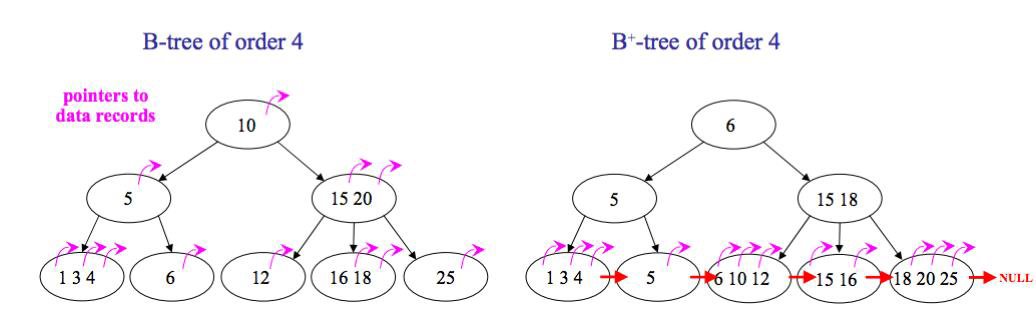
또한 모든 리프 노드가 연결 리스트로 연결되어 있기 때문에 순차 접근이 용이하다는 특징이 있다. B 트리에서 순차 접근을 하기 위해서는 DFS가 필요하다. 순차 접근을 할 필요가 있는 파일 시스템에서는 B+ 트리가 좀 더 선호된다. 이러한 B+ 트리를 활용해 파일 이름을 hash하여 원하는 파일 이름에 해당하는 엔트리를 찾을 수 있다.

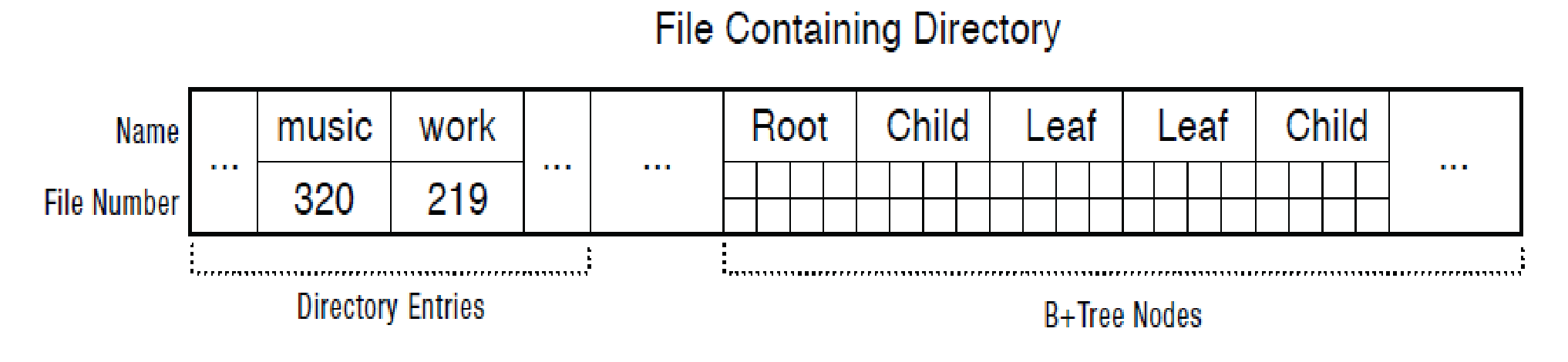
큰 디렉토리는 위와 같은 방식으로 엔트리 탐색을 위한 B+ 트리 구조체를 데이터로 가지고 있어 탐색이 쉽도록 한다.
이외에도 수업 때 여기 링크를 보면서 자세히 설명한 내용이 있다. 해당 내용은 아래에 정리하였다.
'코딩 삽질 > OS 요약 정리' 카테고리의 다른 글
| (2022.05.31) Crash Consistency (0) | 2022.06.01 |
|---|---|
| (2022.05.31) File System (2) (0) | 2022.05.31 |
| (2022.05.27) Caching & Demand Page (2) | 2022.05.27 |
| (2022.05.27) Address Translation (2) (0) | 2022.05.27 |
| (2022.05.27) Address Translation (1) (0) | 2022.05.27 |



