
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- PINTOS
- 일지 시작한 지 얼마나 됐다고
- 핀토스 프로젝트 3
- 자 이제 시작이야
- 황금 장미
- 핀토스 프로젝트 1
- 셋업
- 마일섬
- alarm clock
- 핀토스 프로젝트 4
- 핀토스 프로젝트 2
- 아직도 실험 중
- 파란 장미
- botw
- 글리치
- 끝
- 내일부터
- 제발흰박
- 바빠지나?
- 글루민
- multi-oom
- 가테
- Project 1
- 노가다
- 핀토스 프로젝트
- Today
- Total
거북이의 쉼터
(2022.05.31) Crash Consistency 본문
해당 포스팅에서는 파일 시스템에 데이터 변동이 일어났을 때의 consistency를 보존하는 방법을 다룰 것이다. 다시 cache가 수반된 read와 write의 실행과정을 살펴보면:
- read : 읽고자하는 블록이 cache에 있는지 살펴보고, 있다면 바로 유저에게 반환, 없다면 디스크에서 cache로 해당 블록을 가져오고 반환한다.
- write : write하는 내용은 바로 디스크로 넘어가지 않고 메모리 상에만 변화가 일어났다가 (write behind) OS가 디스크에 쓰기로 결정했을 때 (fsync 등의 동기적 방식 또는 주기적으로 flush되는 비동기적 방식) 변화가 반영된다.
디스크에 write를 최대한 늦추는 이유는 퍼포먼스 증대를 위해서 이지만, 이는 시스템의 안정성과 consistency에 문제를 일으킬 수 있다.
지금까지 살펴본 내용을 하나로 묶어 파일 관련 명령이 실행될 때 일어나는 과정을 자세히 살펴본다. 수업 때 자세히 다룬 내용으로 시험 가능성이 높다. /foo/bar와 관련된 다음의 명령을 실행한다고 생각해보자.
- open /foo/bar
- read data from /foo/bar
- create /foo/bar (/foo가 존재하는 상황에서)
- write data to /foo/bar
각 상황은 다음과 같이 흘러간다.
1. open /foo/bar

open을 하려면 root inode를 읽고, root data (directory 정보)에서 foo의 inode 위치를 알아낸다. foo에서도 마찬가지로 inode를 읽어 data를 찾고, data 내에서 bar의 위치를 찾아 bar의 inode를 읽도록 한다. (총 블럭 read 5회)
2. read data from /foo/bar

위에서 open을 해서 bar의 inode를 읽은 다음에 bar의 내용을 읽으려 한다고 하자. inode에서 bar의 data block 위치를 알아야 하기 때문에 첫 read가 일어나고, data를 실제로 읽기 위해 두 번째 read가 일어난다. 마지막으로 일어나는 write는 파일 메타 데이터 내의 access time을 수정하기 위해 일어나는 것으로, 단순 read 요청에도 block write가 일어나는 것을 알 수 있다. (총 블럭 read 2회, write 1회)
3. create /foo/bar

/foo가 미리 생성되어 있다는 전제 하에 새로운 inode를 할당하고, foo의 디렉토리 데이터 안에 할당된 inode 정보를 기록할 필요가 있다. 일단 foo의 data를 찾기 위해 4번의 read가 일어나고, inode bitmap을 read하여 빈 block을 찾은 뒤, 하나를 bar을 위해 할당하면서 bitmap write가 일어난다. 할당된 inode의 number를 bar의 이름과 매칭하는 페어의 정보가 foo의 directory content에 write되어야 하므로 foo data에 write가 발생한다. bar은 이제 막 생성이 된 파일이므로 inode에 메타 데이터를 초기화와 ctime(creation time)을 기록하기 위해 read와 write가 한 번씩 일어난다. 마지막으로 foo의 메타 데이터는 foo의 데이터의 변경된 내용과 일치하는 메타 데이터를 가지고 있어야 하기 때문에 modify time과 디렉토리 파일 길이 등을 변경하기 위해 마지막으로 foo의 inode에 write가 한 번 일어난다. (총 블럭 read 6회 write 4회)
4. write data to /foo/bar

빈 파일에 쓰기 요청이 들어왔을 때는 데이터 블럭 할당이 요구된다. bar의 inode를 읽고 연결된 데이터 블럭이 없다고 판단되면, data bitmap을 읽어 빈 블럭을 하나 할당하고 할당되었다고 표시한다. 그 후 할당된 블럭에 요청한 내용을 write하고, bar의 inode에 파일의 변화 내용을 반영하도록 메타 데이터를 수정하면 write 요청이 끝나게 된다. 이를 흔히 allocating write라고 한다.
여기까지 정리했으면 이제 crash consistency를 다룰 때가 되었다. 위에서 살펴본 것처럼 간단한 명령에도 파일 시스템 내의 여러 부분에서 write가 일어나는 것을 알 수 있다. 해당 업데이트들을 안정적으로 다루기 위해서는 crash consistency를 요구하게 된다. crash consistency란 atomically update file system from one consistent state to another으로서 실질적으로 메타데이터의가 나타내는 데이터의 상태가 실제 데이터의 상태와 일치하는 것을 의미한다. 예를 들어 파일 A의 inode가 10개의 data block을 가지고 있다는 정보를 가지고 있다면 그 순간에 A는 실제로도 10개의 data block을 가지고 있어야 한다는 것이다. 이러한 정의가 불러오는 흔한 오해가 있다. 이전에 페이지 cache가 변형된 내용을 30초마다 디스크에 write하는 사실을 생각해보자. 만약 디스크에 write가 되기까지 30초 이내에 crash가 나서 cache의 내용이 날아갔다고 하자. 물론 update된 데이터는 날아갔지만, 디스크 내의 해당 파일의 메타데이터와 실제 데이터의 상태가 일치하기 때문에, crash consistency를 위반하고 있다고 할 수 없다. "crash consistency not neccessary mean secure from losing data."임을 반드시 기억하라.
이제 Bitmap (후술 B), Inode (후술 I), Data Block (후술 D) 가 종합적으로 변경될 떄 crash가 나는 상황을 생각해볼 것이다.상황의 단순화를 위해 파일에 allocate write하는 상황을 생각해보자. 파일에 새롭게 블럭을 할당해서 write를 하게 되면, bitmap의 변동, inode 내의 블럭 포인터 할당, 데이터 블럭에 내용 설정으로 B, I, D에 변화가 종합적으로 일어난다. 이렇게 여러 개의 블럭이 update된 상태에서는 여러 개의 블럭이 디스크에 작성될 필요가 있다. 그러나 디스크와 SSD에서의 atomic write의 단위는 블럭(섹터)이기 때문에 여러 개의 섹터 중 일부만 스토리지에 반영이 되고 crash가 난다면 inconsistent한 state가 되기 때문에 문제가 생긴다. 여러 개의 블럭들이 반영이 되는 순서를 정하려고 하더라도 IO scheduler가 퍼포먼스를 위해 해당 순서를 reorder할 수 있고 storage 자체에도 internal hardware buffer가 있어 처리가 flush 되는데에도 reordering이 일어날 수 있다. crash consistency는 reordering에도 불구하고 지켜져야 하는 것이기에, 특정 하드웨어 디자인에 의존하지 않아야 한다.
디스크에 BID 중 일부만이 반영된 상태로 crash가 나는 시나리오를 생각해보자. B', I', D'이 새롭게 변경된 상태라고 하면 총 8개의 경우의 수가 있을 수 있다. 이 중 BID와 B'I'D'은 consistency에 문제가 없으니 생략하면 나머지 6개의 경우가 문제이다. 우선 가장 간단히 하나의 변화만 방영된 경우를 보면 다음과 같다.
1. B'ID
B'을 작성한 직후 crash가 나서 디스크에 B'만 반영이 된 경우 inconsistent하다. 실제로 할당되지 않은 공간이 사용되고 있다고 표기되기 때문에 디스크 공간이 낭비된다.
2. BI'D
I'을 작성한 직후 crash가 나서 디스크에 I'만 반영이 된 경우 inconsistent하다. 파일의 inode 상으로는 새로운 블럭이 할당되어 있다고 표시하지만, 실제로 그 안은 쓰레기 데이터가 들어있게 되고, bitmap에서도 해당 블럭이 미할당이라고 표기하기 때문에 일관성이 깨졌다는 것을 의미한다.
3. BID'
D'이 작성된 직후 crash가 나서 디스크에 D'만 반영된 경우, 데이터는 디스크에 있지만, 이를 가르키는 inode가 없고, bitmap상으로도 할당되어 있지 않다고 표기하기 때문에 문제가 없다. allocating write의 경우 새로운 내용이 적히지 않고 손실된 경우이다. 다만 consistency 상으로는 문제는 없다.
두 개의 부분이 성공하고, 하나만 실패할 경우에는 다음과 같다.
1. B'I'D
파일 시스템 메타 데이터의 일관성은 보장된다. 새로운 블럭은 bitmap 상으로 할당이 되었다고 표기되어 inode 상에서 사용된다. 다만 새로운 블럭의 내용은 쓰레기 값이 들어있게 되어 유저에게 이상한 데이터값이 노출될 수 있다.
2. BI'D'
inode가 디스크의 데이터를 제대로 가르키고 있지만, bitmap과 inode간의 내용에 일관성이 없다. 파일 시스템은 bitmap을 고침으로서 해당 문제를 수정할 수 있다.
3. B'ID'
inode와 bitmap 간의 내용 불일치로 일관성을 갖지 않는다. 블럭의 내용이 기록되고 bitmap도 사용중이라고 하지만 inode의 정보가 소실되었기에 해당 블럭이 어디서 사용되는 것인지 알 방도가 없다.
간단한 경우에도 어떤 부분이 디스크에 반영되는지의 여부에 따라 여러 문제가 발생하는 것을 볼 수 있었다. 파일 시스템 자료 구조 간 불일치가 있기도 하며, 공간 누수가 발생하거나 유저에게 의미 없는 데이터가 보여지는 문제도 있었다. 이러한 crash consistency 문제를 해결하기 위해 file system checker (FSCK)를 도입하였다. FSCK는 시스템이 부팅될 때, inconsistency를 발견하기 위해 파일 시스템 전체를 순회하며 검사한다. inode pointer, bitmap, directory entry, inode reference counts 등을 살펴보면서 문제가 발견될 경우 자동으로 이를 고치려고 노력한다.
B'ID의 경우에는 할당되었다고 표시된 블럭을 사용하는 inode가 없기 때문에 잘못된 bitmap을 수정할 수 있다. BI'D'의 경우에도 I'과 D'에 기반해 할당이 된 블럭에 해당하는 index의 bitmap을 수정할 수 있다. FSCK는 제대로 작동하게 만들기도 쉽지 않지만, 근본적인 문제를 갖는다. 위에서 언급한대로 B'ID' 같은 경우는 수정할 수 없으며, 너무 느리다는 것이 가장 큰 문제이다. FSCK는 큰 디스크에 대해서는 한 번 실행될 때마다 몇 시간씩 수정 과정을 거치기도 한다. 이러한 점에서 FSCK가 매번 리부팅마다 돌아간다면 끔찍할 것이다. 이를 우회하기 위해 실질적인 사용을 위해 flag가 있어 매 리부팅 때마다 실행되는 것은 방지한다. 그런 것이 아니더라도 한 번 실행될 때마다 굉장히 오래걸리는 문제는 여전하다.
FSCK의 한계를 극복하기 위해 새로운 해법을 도입한 것이 바로 journaling이다. 저널링의 핵심은 파일 시스템에 작성하기 전에 하려는 행동(Intent)을 디스크에 작성하는 것이다. 즉, 자료구조를 갱신하기 전에 수행하고자 하는 작업을 요약해서 기록하는 것이다. 때문에 이를 Write Ahead Logging이라고 부르기도 한다. Crash가 일어나면 로그를 보면서 어떤 행동이 일어나고 있었는지를 살피고 복구할 수 있도록 한다. intent가 다 작성되기 이전에 crash가 일어난 경우에는 아무 행동도 하지 않으며, intent가 다 작성된 뒤에 crash가 났을 경우, 해당 intent가 온전히 이루어지도록 작업을 다시 진행한다.
저널링의 구체적인 과정을 살펴보자. 저널링에서는 디스크의 일부분을 저널이라는 영역으로 분리한다. 메모리에서 블럭의 변화가 일어난 것을 원본 블럭에 반영하기 전에 저널에 저널 헤더와 함께 변화된 블럭을 기록한다.
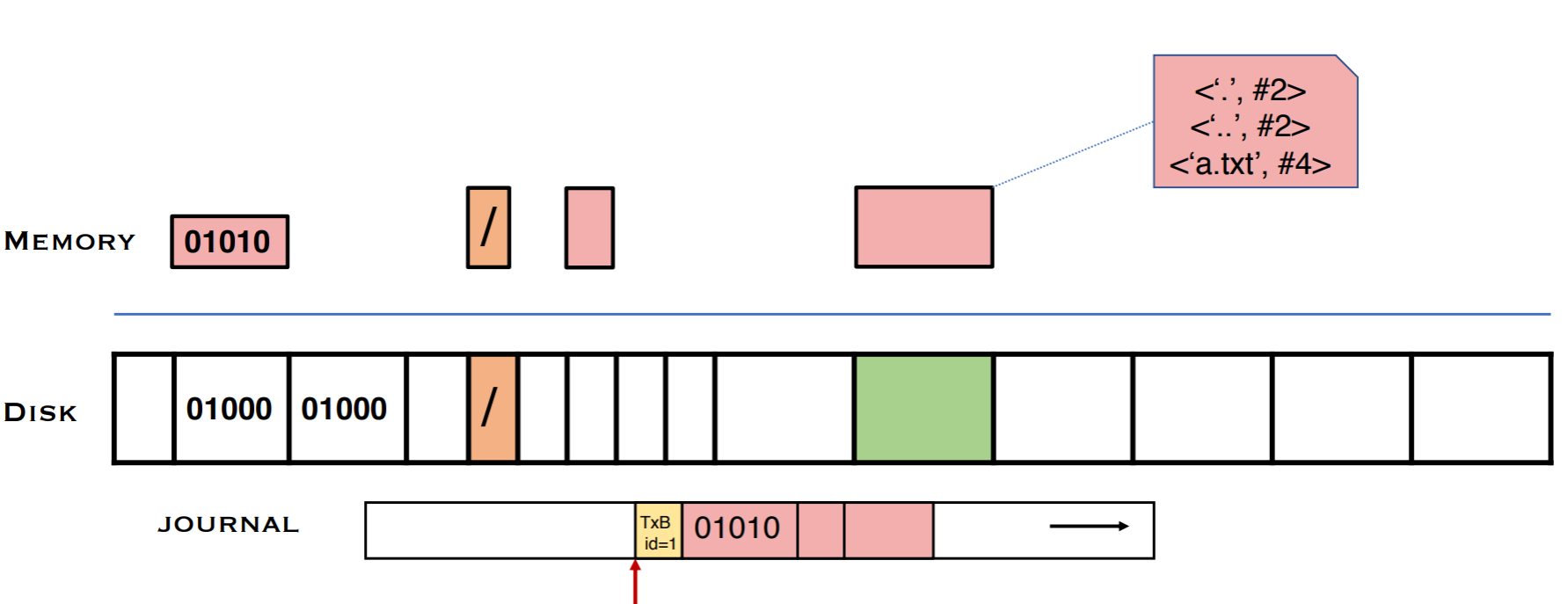
다 작성했다면 journal commit block으로 저널을 닫는다. 만약 crash가 journal commit block을 쓰기 전에 어느 순간에 일어났다면 어떤 작업도 일어나지 않게 함으로서 crash consistency는 유지된다. commit block이 없으면 전체가 반영이 되지 않았다고 가정하고 저널의 내용을 무시한다. 이 때문에 journal header와 B, I, D의 순서는 바뀌어도 무관하나, journal commit block은 반드시 ordered 되어야 하며, 위의 스텝과 merge되어서는 안된다. ordering을 위해 journal은 모든 data가 작성되었는지 확인해야 하므로 모든 DMA가 끝날 때까지 기다린 뒤, 모든 data를 flush하도록 device에 issue한 뒤에야 journal commit block을 쓸 수 있다. journal commit block은 atomic operation을 위해 단일 섹터 크기이며, 작성이 된 여부에 따라 crash 이후 해당 작업을 할지가 결정된다. commit block이 제대로 된 commit block이라는 것을 표기하기 위해 header와 특정 id 매칭을 하거나 BID의 checksum을 만들어 넣어놓기도 한다.
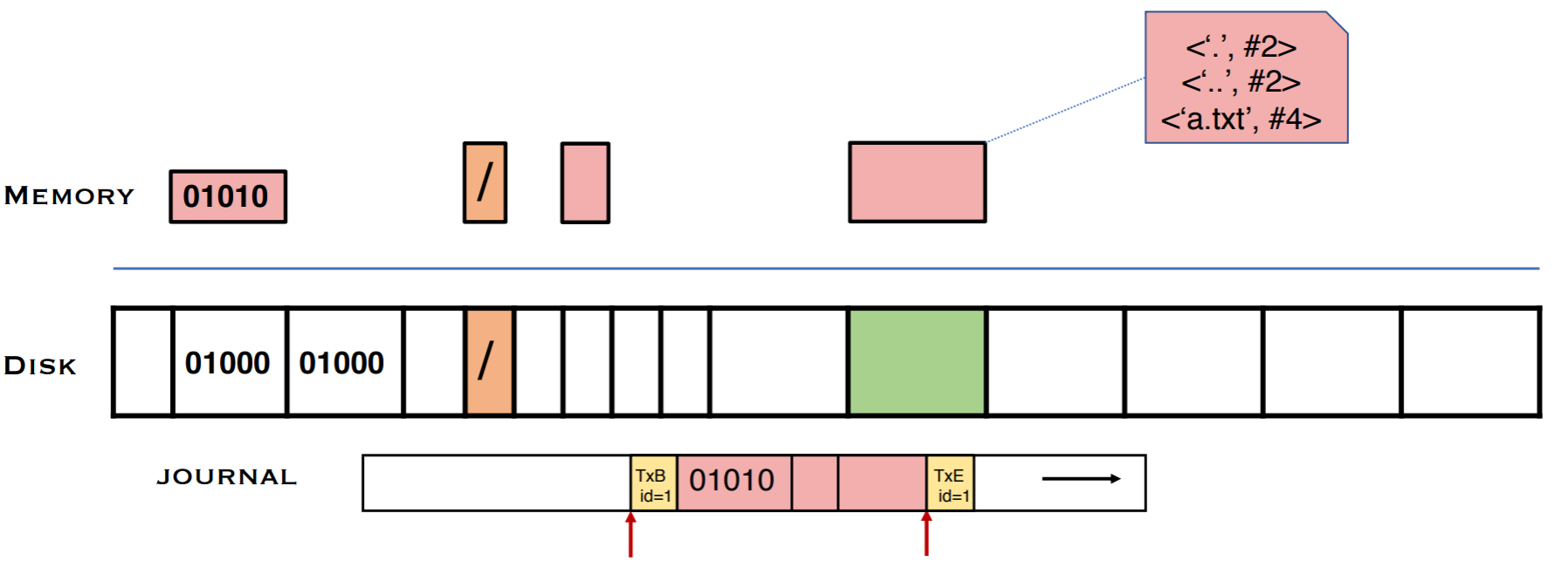
이 뒤에는 저널의 결과가 디스크에도 반영된다. 이를 checkpointing이라고 한다. 반영하는 중간에 crash가 나더라도 반영할 내용이 저널에 살아있기 때문에 복구할 수 있다. BID의 순서가 상관이 없던 이유 또한 어차피 중간에 날아가더라도 모든 것을 복구할 수 있기 때문이다.
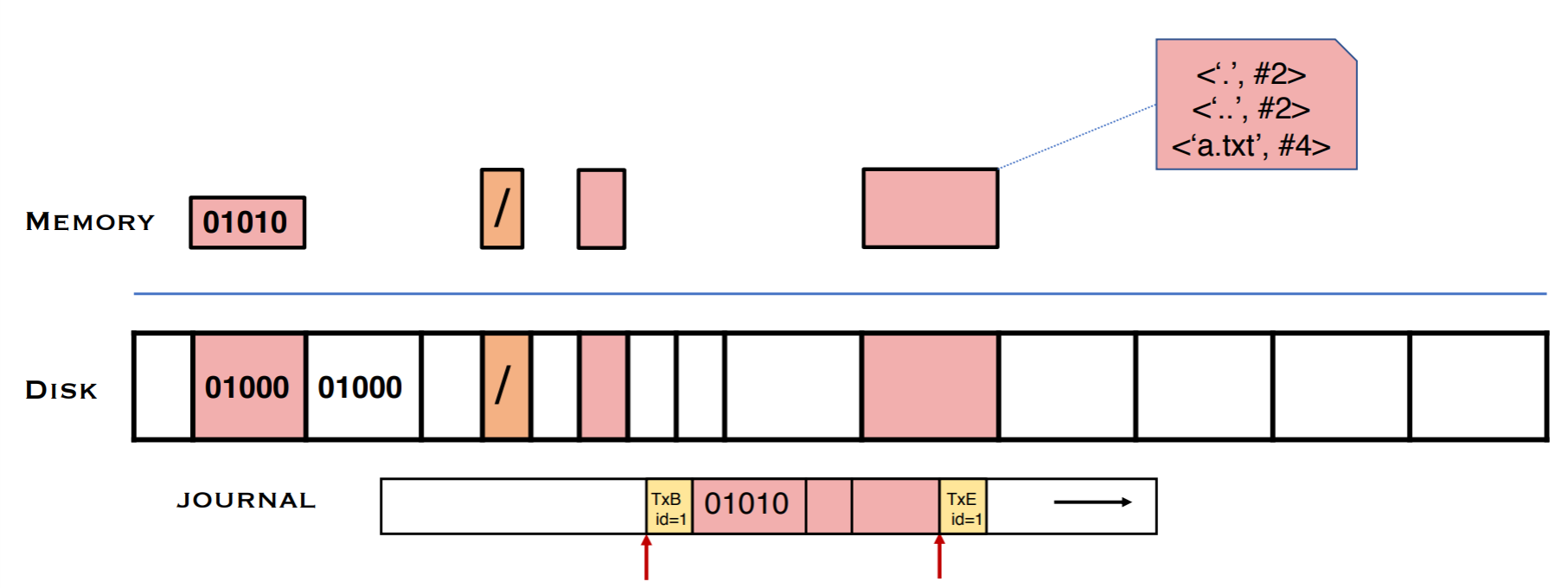
마지막으로 모든 결과가 디스크에 반영이 되었다면 그제서야 저널을 날려서 저널의 공간을 확보한다. 저널의 내용이 디스크에 작성되기 이전에 날리면 중간 crash에 대처할 수 없으므로 날리는 시점은 반드시 저널의 모든 내용이 반영된 이후여야 한다.
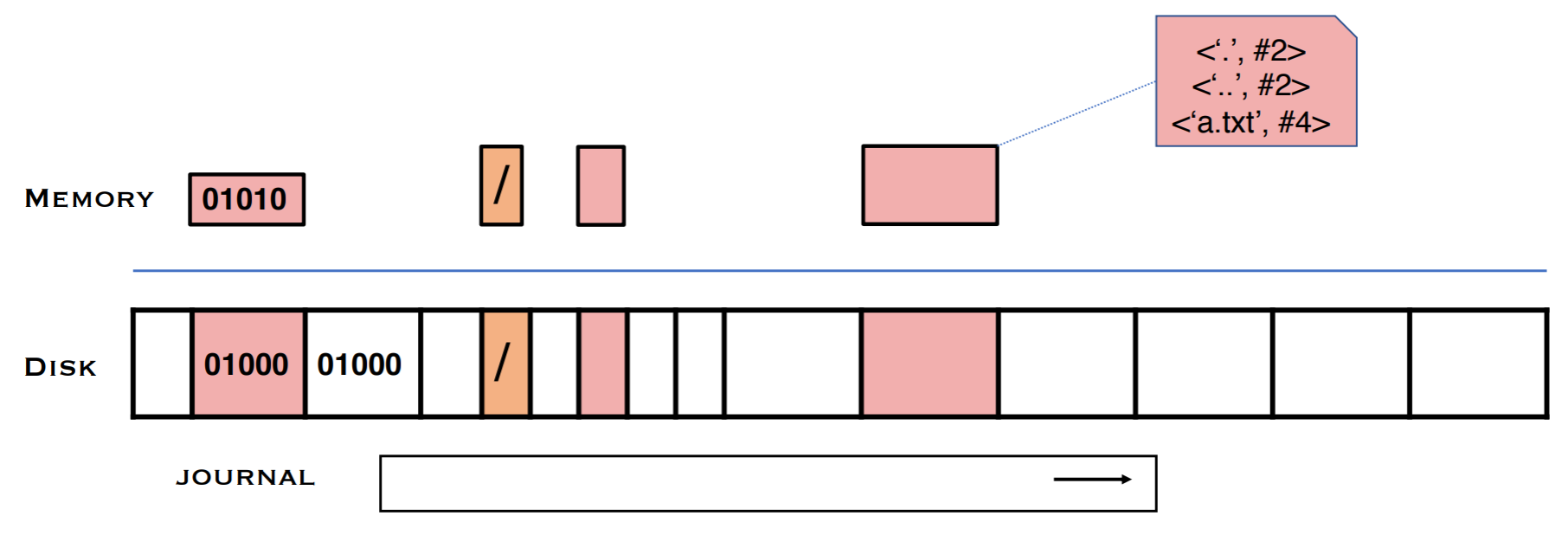
FSCK의 극한의 복잡성과 느린 속도와 비교해 저널링은 감안할 정도의 속도와 복잡성을 지니고 있기 때문에 저널링을 많이 사용하는 편이다. 저널링의 단점은 같은 내용을 저널에도 작성해야 하는 extra write이다. Crash가 날 경우, 앞에서 언급했듯, 로그를 순회하면서 로그에 기록된 내용이 디스크에도 반영되도록 operation을 "redo"하는 recovery 과정을 가진다. 저널링에서 일어나는 write 순서를 요약하면 journal write - journal commit - FS write (checkpointing) - journal clean 순으로 일어난다.
현대 파일 시스템인 Ext4에서는 저널링의 단점인 extra write를 극복하기 위해 저널링의 모드를 가지고 있다. Ext4의 mount 옵션을 보면 journal / ordered / writeback의 모드를 지원한다. journal 모드는 지금까지 설명했던 정석적인 저널링이 일어나는 것이고, ordered는 default 모드로서, 모든 데이터가 저널링되는 것이 아닌, 파일의 메타 데이터에 해당되는 부분만이 저널에 기록되게 된다. 해당 모드가 존재하는 이유는 performance 때문이지만, 이로 인해 consistency를 온전히 지원하지는 않게 되었다. 때문에 B'I'D는 방지하지 못한다. Ordered mode에서는 crash가 날 때의 consistency를 보전하는 것이 프로그래머/application의 의무가 된다. 이는 어떻게 할 수 있을까?
예를 들어 단순화를 해서 storage가 1B를 atomically하게 바꿀 수 있다고 하자. 파일의 애초의 내용이 Foo이고 이를 Bar로 바꾸고자 한다. Consistency를 위해서는 Crash가 나더라도 파일의 내용이 Foo 또는 Bar 만 보이게 하도록 하고 싶다. 단순히 write(/a/file, "Bar")만 하면 Fao 또는 For 같은 중간 결과물이 나올 수 있다.
Try 1 (Rollback logging)
그래서 보다 정확하게 이를 구현하기 위해서는 로그 파일을 생성하고 로그에 원본 파일 내용을 저장한뒤, 원본 파일에 변경하고자 하는 내용을 작성하는 방법을 사용한다.
creat(/a/log)
write(/a/log, "Foo")
write(/a/file, "Bar")
unlink(/a/log)이 방법도 여전히 문제가 있다. 로그 파일을 생성해 로그 파일에 원본 내용을 작성하기 이전에 원본 파일에 작성하는 reordering이 일어나고, write가 되는 도중 crash가 나게 되면 파일은 중간 결과물을 보여주게 된다. 핵심적인 문제는 reordering이 발생하는 것이다.
Try 2 (Rollback logging with ordering)
이를 방지하기 위해 사용하는 것이 fsync이다.
creat(/a/log)
write(/a/log, "Foo")
fsync(/a/log)
write(/a/file, "Bar")
fsync(/a/file)
unlink(/a/log)fsync는 해당 내용이 반드시 디스크에 작성되기를 강제하기 때문에 log 생성 후 log에 작성하고 fsync를 한다면 로그에 write되는 것이 원본 파일에의 write보다 빠르게 된다. 따라서 원본 내용이 로그에 기록된 이후에 파일에 변경 내용을 작성하게 되고 해당 작성 이후에도 fsync를 해서 디스크에 바로 반영을 해 주는 방식은 괜찮아 보인다. 두 번째 fsync는 디스크 내에 파일에 write가 된 내용이 반영되는 것보다 로그 파일을 삭제하는 것이 먼저 일어나는 것을 방지한다. 그러나 이 방식 또한 문제가 있다.
로그 파일을 생성할 때 변경된 디렉토리의 내용이 디스크에 반영이 되지 않되는 경우, /a/log가 /a/ 디렉토리에 생성된 것이 반영이 안 되어 /a/log 파일을 찾지 못해 crash 이후 로그 파일을 찾아 복구하지를 못해 중간 결과물이 보일 수 있다. 따라서 디렉토리에도 fsync를 적용시켜야 할 필요가 있다.
creat(/a/log)
write(/a/log, "Foo")
fsync(/a/log)
fsync(/a/)
write(/a/file, "Bar")
fsync(/a/file)
unlink(/a/log)물론 log의 생성 직후에 디렉토리를 fsync할 수 있으나, performance 차원에서는 최대한 fsync를 미루는 것이 유리하다. 이를 맞게 구현하기 위해서는 반드시 atomicity, ordering, durability, directory에 대한 이해가 필요하다.
'코딩 삽질 > OS 요약 정리' 카테고리의 다른 글
| (2022.05.31) File System (2) (0) | 2022.05.31 |
|---|---|
| (2022.05.30) File System (1) (0) | 2022.05.30 |
| (2022.05.27) Caching & Demand Page (2) | 2022.05.27 |
| (2022.05.27) Address Translation (2) (0) | 2022.05.27 |
| (2022.05.27) Address Translation (1) (0) | 2022.05.27 |



