
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 핀토스 프로젝트
- 파란 장미
- 바빠지나?
- botw
- 아직도 실험 중
- 핀토스 프로젝트 3
- 황금 장미
- 끝
- multi-oom
- 제발흰박
- alarm clock
- 셋업
- 가테
- PINTOS
- 글리치
- 핀토스 프로젝트 2
- 노가다
- 내일부터
- 자 이제 시작이야
- 일지 시작한 지 얼마나 됐다고
- 핀토스 프로젝트 1
- 핀토스 프로젝트 4
- Project 1
- 마일섬
- 글루민
- Today
- Total
거북이의 쉼터
(2022.05.31) File System (2) 본문
대체 핀토스 4번은 언제쯤 유지보수 끝날까? 암튼 시작.
Hard Link
link()는 system call의 일종으로 old file과 new file을 연결하는 역할을 한다. 이 때 생성되는 링크의 종류는 Hard Link이며, new file을 old file처럼 사용할 수 있게 한다. 그 내부에서는 실제로는 두 파일이 같은 inode를 가리키게 된다. ls -i 를 하면 inode value를 확인할 수 있는데, hard link된 파일들에서는 이들이 같은 값을 나타내는 것을 볼 수 있다. 링크된 파일들은 inode 단에서 같은 inode로 연결되기 때문에 old file과 new file은 차이가 없게 된다.
링크가 생성되면 inode의 reference count를 증가시킨다. reference count는 파일의 링크된 횟수를 나타내며, stat file을 했을 때 "Links"가 뜨는 것이 reference count이다. 기본적으로 파일의 Links는 1이다. 링크되어 있는 파일을 삭제하더라도, 지운 뒤의 inode의 reference count가 0이 아니라면 완전히 삭제되지 않고, reference count가 0에 도달해야만 해당 inode와 연결된 data block을 완전히 삭제한다. 링크를 끊기 위해서는 unlink()를 사용해야 한다. unlink는 inode 내부의 reference count를 확인하고 파일의 이름과 inode number 사이의 관계성을 제거하고 reference count를 감소시킨다.
Symbolic Link (Soft Link)
Symbolic Link은 Hard Link의 제약을 극복하기 위해 개발되었다. Hard Link는 디렉토리로의 링크를 생성할 수 없고, 다른 파티션에 위치한 파일로 링크할 수 없는데, symbolic link에서는 모두 가능하다. hard link과 soft link의 핵심적인 차이는 inode를 원본 파일과 별개로 생성한다는 것이다. 내부적으로는 symbolic link 파일의 inode가 기존 파일의 inode를 간접적으로 참조하는 식으로 운용된다. 이러한 차이로 인해 원본 파일의 inode의 reference count도 증가하지 않으며, 원본 파일이 지워질 경우, symbolic link된 파일 자체는 남아있으나, 정상적으로 기능하지 않게 된다(dangling reference). Symbolic Link는 ln에 -s 옵션을 주어 생성할 수 있다.
어떤 파일의 Symbolic Link의 Hard Link를 생성하면 해당 Hard Link는 Symbolic Link의 inode를 공유하게 된다. 따라서 원본 파일의 reference count는 여전히 증가하지 않는다. 수업 때 또 잘못 알려준 내용이다 썩을.... 교수가 입벌구라 맨날 그짓말이다. 아는 척이 오지니 신뢰할 만한게 못 돼...
Storage는 느리기 때문에 DRAM caching이 performance를 위한 핵심이 된다. 이를 위해 file buffer cache가 있다.
File buffer cache (page cache)
엄밀히 말하면 리눅스에서는 구분하고 있지만 그냥 동일한 개념이라고 취급하자. 디스크에서 직접 파일 내용을 가져오는 것은 느리며, 메모리에 해당 내용을 cache하면 spatial & temporal locality에 의해 효율적인 작업이 가능하다. 물론 spatial을 고려하기 위해서는 prefetching 과정까지 요구되니 일단 생략하고 temporal locality만 생각하도록 한다.
File Cache는 system wide이다. OS는 해당 cache를 per process가 아닌 global하게 관리한다. 이 때문에 File Cache는 여러 프로세스에 의해 share될 수 있다. caching의 문제는 DRAM이 한정되어 있기 때문에 file buffer cache가 VM과 경쟁해야 한다는 것이다. 이 문제로 인해 memory presure가 생기면 메모리에서 cache를 해제해주는 replacement algorithm을 도입할 필요가 있다. 주로 LRU가 사용된다.
큰 파일에 대해 작업을 하고 terminate한 프로세스를 생각해보자. 해당 파일이 버퍼 cache에 올라와 있다면 프로세스가 종료된 이후에 이 메모리 영역은 어떻게 될까? OS는 해당 page cache를 free하지 않고 retain한다. 왜 메모리 상에 당장 필요없는 정보를 계속 올려놓는것일까? 메모리가 충분하다면 OS는 최대한 다시 돌아올수 있는 프로세스를 위해서 남겨놓는다. 긍정적으로 생각하면 프로세스가 같은 파일을 사용할 여지가 있기 때문이다. page cache는 per process가 아닌 global한 자원이니 가능한 말이다. 또한, dirty bit가 켜져있다면 프로세스가 종료되는 시점에 free가 바로 될 경우 시간이 오래 걸릴 수 있기 때문에 최대한 메모리에 page cache를 잔류시키는 것이다.
data와 code는 file backed memory이지만 page cache는 아니라고 생각하자.
Caching Write
application의 write는 cache에 일어나지만 몇몇 application은 디스크에 해당 내용이 작성되는 것을 가정한다. fsync는 이를 직접적으로 행하게 하는 system call이며, OS 또한 디스크와 page cache의 unsynchronized된 상태가 유지되지 않도록 정기적으로 디스크에 변화를 반영한다. OS는 uncommited block의 queue를 관리하면서 이를 주기적으로 flush한다. block이 해당 주기 내에 여러번 변하더라도 실제 반영은 최종적인 수정 내용 한 번만 반영되기 때문에 IO는 최소화된다.
그러나, 30초마다 작성하는 것은 어찌보면 30초간의 구간은 상실할 수 있다는 것을 의미한다. 때문에 이는 Unreliable하지만, 다른 방법은 performance 저하를 불러오기 때문에 실용적이다. 정말로 data를 persistent하게 하고 싶다면 직접적으로 fsync를 호출함으로서 명시적으로 디스크에 작성하도록 하는 방식이 있다.
Read Ahead
random access와 sequential access 중에서는 sequential access가 흔한 편이다. 이 때문에 spatial locality가 발생하고 이러한 특징을 활용해 효율성을 증대시키는 방법 중 하나는 read ahead 이다. Read ahead는 파일 시스템은 어플리케이션이 요청하지 않은 파일의 다음 블럭까지 요청하기 이전에 미리 file cache에 preload한다. "다음 블럭"이란 파일 내에서 contiguous한 블럭으로, storage 내부에서는 연속적이지 않을 수 있다. 해당 작업은 프로세스가 요청한 블럭으로 작업을 하는 도중에 일어날 수 있기 때문에 IO overlapping이 가능하다.
File Sharing
File sharing은 프로세스 간 통신과 동기화의 근간이 된다. 간단한 lock이나 spin lock은 프로세스간 메모리 공유가 되어야 가능하지만, 파일 sharing은 보다 쉽게 할 수 있기 때문이다. 예시로 lock 파일이 존재할 때 프로세스의 행동을 정해 둔다면 동기화를 할 수 있다. 파일이 cache에 있을 때 share하는 방법은 메모리 share과 같은 방식으로 매핑을 공유하면 된다.
이제 파일이 공유된 상황에서 semantic of concurrent access를 알아봐야 한다. Sharing이 모두 writable sharing이어서 COW 같은 일이 벌어지지 않는다고 가정할 때,
- 한 프로세스가 읽을 때 다른 프로세스가 쓰려고 하면 어떻게 될까?
- 두 프로세스가 동시에 파일에 쓰려고 한다면?
- 이를 조율하기 위한 해법은?
DRAM에 한 프로세스가 쓴 내용은 cache coherence protocol 동시에 다른 프로세스에게 보여진다. 이는 coordination 메카니즘이 없다는 것을 의미한다. 두 프로세스가 한 파일을 write 목적으로 열 때도 마찬가지로 어떠한 제약없이 둘 다 writable하며 coordination이 일어나지 않는다. 이를 정리하면 동시 접근에 대해 파일 시스템은 no synchronized access without any coordination을 택한다. 이는 마치 thread의 동시 접근에 대해 concurrency를 정리해야 하는 주체가 OS가 아닌 어플리케이션인것과 같다. 파일 동시 접근을 coordinate하는 주체는 파일 시스템이 아닌 어플리케이션이다. 해당 coordination은 반드시 필요하다. 현실에서 coordination이 필요한 예시를 들어보면 apache 웹 서버가 configuration file을 write 목적으로 부르고, 쉘에서도 같은 파일을 write하려고 연 상황을 생각할 수 있다.
Concurrency를 위해 리눅스에서는 fcntl file lock을 제공한다 (OS supports file lock mechanism). 해당 system call은 파일 시스템에 concurrency를 제공할 수 있으며 파일을 공유하는 두 프로세스 사이에서 일종의 통신을 가능하게 한다. 해당 semantic control 없이 파일 시스템은 동시 접근되는 것을 허용하기 때문에 원하는 순서대로 프로세스가 작동되길 원한다면 fcntl을 통해 lock을 걸어주어야 한다. 이외에도 락 파일을 이용해서 프로세스 상의 프로토콜에 의해 동기화하는 방식도 생각할 수 있다.
HDD의 동작 방식
하드디스크는 mechanical part인 arm이 움직이면서 platter 내의 정보를 읽는다.

같은 회전 반경에 놓여서 arm을 움직일 필요가 없는 섹터의 집합을 트랙이라고 하며, 여러 platter 내의 같은 회전 반경을 갖는 트랙의 집합을 같은 실린더 그룹에 있다고 말한다.
하드디스크의 performance는 파츠의 물리적 움직임에 영향을 받는다.
1. seek time
arm을 원하는 실린더로 가져가기까지 걸리는 시간. 실린더 거리에 의해 결정되는 시간이다. (완전 선형적이지는 않음)
2. rotational delay
arm의 head 아래로 원하는 섹터가 회전하기까지 걸리는 시간. 디스크의 RPM에 의해 결정된다.
3. transfer time
필요한 정보를 섹터에서 실제로 읽어서 옮기는 시간
1, 2, 3이 모여 한 섹터를 읽을 때의 전체 시간을 이룬다. 이 중에서 가장 느려 전체 시간에 영향을 많이 주는 것은 seek time으로, arm의 물리적인 움직임이 가장 시간을 많이 잡아먹기 때문에 HDD의 퍼포먼스를 위해서는 seek time을 어떻게 줄이느냐가 관건이다.
이제 서로 다른 두 파일 시스템을 살펴보면서 파일 디자인을 심층적으로 생각해보자.
원본 UNIX FS
원본 UNIX FS 같은 경우는 간단하고 elegant하다. On Disk Layout은 이렇게 생겼다.

구성은 Data Block, Inode, Free List, Super Block이다. Super Block은 Free List와 Inode와 Data Block이 어디에서부터 시작하는지를 가르킨다. Free List는 할당되지 않은 블록을 연결 리스트로 관리하고, Inode는 이전까지 살펴보았던 inode array를, data blocks는 실제 데이터가 들어가 있는 블록의 집합이다. 해당 파일 시스템의 주요한 문제는 느리다는 것이다. 또한 Sequential Disk Access에도 하드디스크를 완전히 utilize하지 못한다. 해당 시스템이 왜 느린지를 분석해보면 크게 3가지 요인을 잡을 수 있다.
1. Too Small Blocks (512 Byte)
블럭 크기가 작기 때문에 파일의 인덱스가 너무 커지게 되고, indirect blocks를 많이 요구하게 되면서 transfer rate가 낮아지게 된다.
2. Unorganized Freelist
Free List는 첫 free block을 가르키고, 다음 free block이 어디인지를 가르키는 연결 리스트 형태로 되어 있다. 이 때문에 할당이 될 때 파일에서 연속된 데이터 블록이 디스크 상으로 멀리 떨어져 있어 Sequential Access에도 적지 않은 비용이 소모되기도 한다. 또한 이런 방식에서는 시간이 지날수록 연결 관계가 복잡해지고 free block이 fragmented되는 aging 문제가 발생한다.
3. Poor Locality
파일 연산에 있어서 inode와 data block이 모두 필요함에도 불구하고, inode와 data block이 서로 멀리 떨어져 있으면서 locality를 챙기지 못했다. 이 때문에 enumeration에서 poor performance를 보인다.
FFS (Fast File System)
FFS는 원본 UNIX FS가 느려지는 원인을 하나씩 타파한다. 기존 있던 시스템을 개선할 때도 이 방식을 주로 채택한다고 한다.
- measure State Of The Art
- Indentify & understand fundamental problems
- Get idea & build better system
핵심은 FS 구조와 allocation policy가 디스크의 특징을 활용할 수 있도록 설계하는 것이다.
1. Too Small Blocks (512 Byte)
블럭 사이즈가 너무 작다고 판단하여 블럭 사이즈를 늘려보았다. 블럭의 크기를 늘릴수록 file bandwith가 증가하는 것을 볼 수 있다. 이는 같은 용량의 파일에 대해서 작업할지라도 블럭이 분할되어 있을수록 inode lookup 등의 메타 데이터 작업이 늘어나고, IO request 수와 DMA 횟수 또한 늘어나기 때문이다. 문제는 큰 크기의 블럭을 사용하면 고질적인 internal fragmentation 문제로 인해 공간 낭비 또한 심해지게 된다.
해당 문제를 해결하는 방법은 malloc에서 아이디어를 찾았다. 바로 fragments 기법이다. Allocation Unit과 Management Unit을 분리해서 생각하는 것으로, 큰 블럭 사이즈를 할당하는 것을 기본으로 하되, 해당 블럭이 작은 부분인 fragments로 쪼개질 수 있는 것을 허용하는 것이다. 작은 조각들은 작은 파일 또는 파일의 끝 부분에만 사용되는 것을 허용한다. 해당 방식의 장점은 큰 파일에 대해서 높은 transfer speed를 가진다는 것과 작은 파일이나 파일의 끝 부분에서 낭비되는 공간을 최소화한다는 것이다.
fragment 사용 예시를 더 자세히 살펴보자.
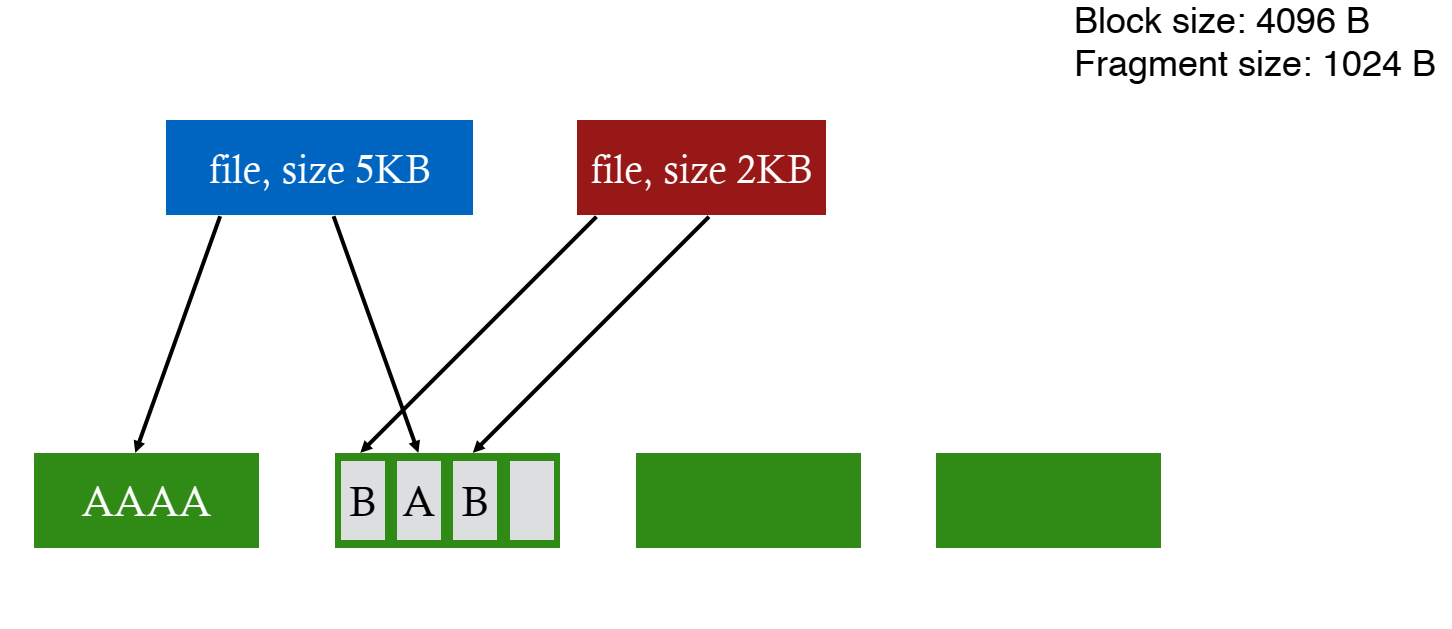
위의 상황에서 파란 색 파일을 1KB 더 늘리고 싶다면 블럭의 남은 fragment를 할당하면 된다.

한 번 더 늘리는 경우에는 새로운 블럭의 한 fragment를 할당한다.

마지막으로 한 번 더 늘려서 fragment에 분할된 파일의 용량이 블럭 사이즈에 도달했다면 새로운 블럭 하나를 할당해 해당 파일이 온전히 사용할 수 있도록 한다.
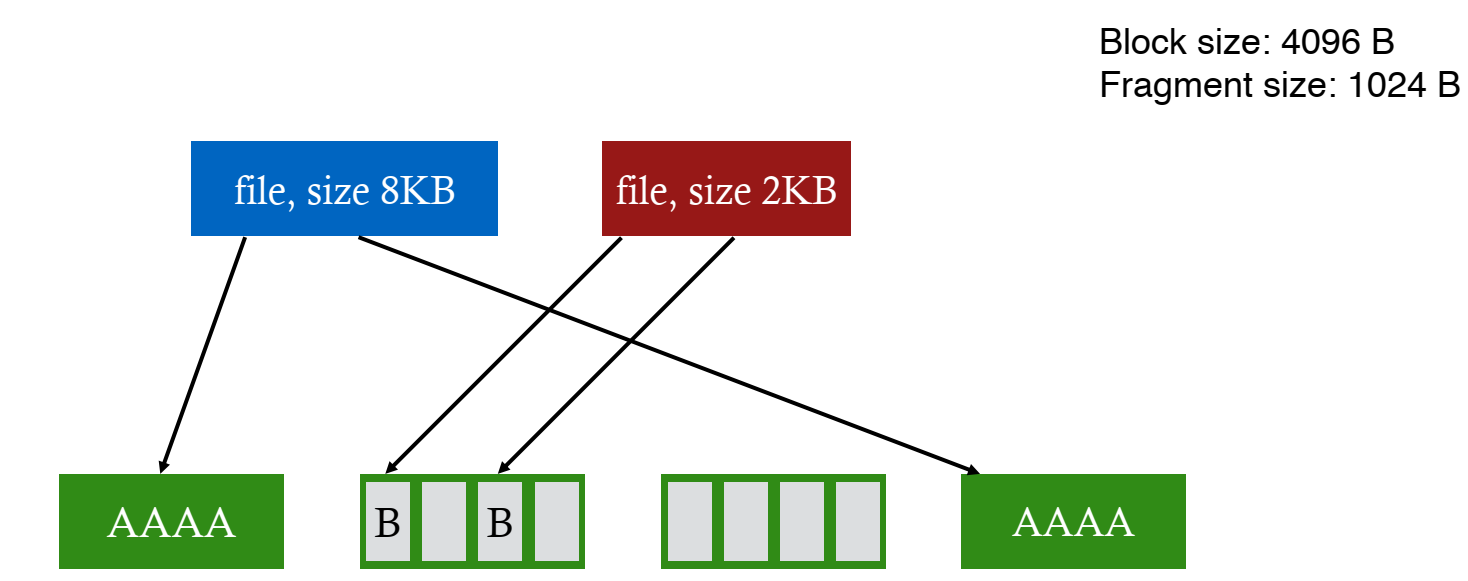
FFS는 fragment와 블럭을 관리하는 구조를 가지고 있지만 깊게는 살펴보지 않을 것이다.
2. Unorganized Freelist
Free List는 초기에는 깔끔하게 정리되어 있지만 시간이 갈 수록 allocation과 free가 반복되면서 fragmentation이 발생한다. 때문에 free block을 찾기 위해서 free list를 back and forth로 순회할 필요가 생겨서 performance degradation이 불가피해진다. 실제로 새로운 파일 시스템에서는 17.5%의 disk bandwidth를 달성하지만 몇 주만 지나도 3%로 떨어지는 것을 볼 수 있다. 이를 해결하기 위해서 compact (defragment) 를 주기적으로 할수도 있었지만 해당 작업이 실행되는동안 incoming IO를 방해하여 disk bandwidth를 제한한다.
이에 새로운 자료구조인 bitmap을 사용해서 할당 여부를 표시하게 함으로 문제를 해결한다. bitmap의 각 비트는 해당 인덱스의 블럭이 free인지의 여부를 알려준다. 이 방식으로 contiguous한 0을 찾음으로 contiguous block을 찾기 쉬워졌으며, bitmap의 전체 용량도 작으므로 전체를 메모리에 옮겨서 사용하는 것도 가능하다.
3. Poor Locality
inode의 끄트머리에서 data block을 읽는 것은 빠르지만 inode 초반부에서 data block을 읽는 것은 느렸다. 이는 앞서 언급한 HDD의 특징 때문이다. seek time에 의해 영향을 받는 HDD의 특성상 inode와 data가 같은 실린더에 속하지 않았기 때문에 느려진 것이다.
끝내 FFS의 개발자들은 연관된 데이터를 같은 실린더 그룹에 넣어두면 seek time이 최소화할 수 있다는 점을 착안했다. 같은 실린더 그룹 내의 블럭은 seek time 없이 접근할 수 있고, 다음으로 빠른 곳은 인접한 실린더에 위치한 블럭이다. 따라서, 연관된 것은 최대한 같은 실린더 그룹에 넣으려고 하고, 연관되지 않은 것은 최대한 다른 실린더에 넣으려고 한다.
이를 풀어 설명하면 :
- Sequential Block은 인접한 섹터에 넣으려고 한다. Spatial Locality가 적용된다면 이득을 본다.
- 파일의 inode와 파일의 실제 데이터 블록을 같은 실린더 그룹에 넣으려고 노력한다.
- 같은 디렉토리 내에 있는 inode는 같은 실린더에 넣으려고 한다. (디렉토리 순회 명령어가 많은 특성에 유리)
이 중 2번째 사항을 자세히 보자. 어떻게 필요한 inode를 필요한 데이터 블럭과 같은 실린더에 넣을 수 있을까? 해법은 전체 파일 시스템을 나누어 각 실린더 그룹에 bitmap, inode, data block을 따로 유지하는 것이다. FS는 초기화되며 얼마나 많은 실린더 그룹이 생길 수 있는지를 확인하고, bitmap, inode, data block을 분할해 각 그룹에 위치시킨다. 각 실린더 그룹을 작은 유닉스 파일 시스템처럼 관리하는 것이다. 이를 block group이라고 한다.
오늘날에는 디스크를 주로 사용하지 않아 디스크의 특성을 고려해 제작된 FFS는 SSD등의 다른 디바이스에서 optimal하지 않다 (F2FS, LFS 등의 다른 파일 시스템이 사용됨).
'코딩 삽질 > OS 요약 정리' 카테고리의 다른 글
| (2022.05.31) Crash Consistency (0) | 2022.06.01 |
|---|---|
| (2022.05.30) File System (1) (0) | 2022.05.30 |
| (2022.05.27) Caching & Demand Page (2) | 2022.05.27 |
| (2022.05.27) Address Translation (2) (0) | 2022.05.27 |
| (2022.05.27) Address Translation (1) (0) | 2022.05.27 |



